Redshiftのデータ共有機能とAWS Lake Formationでアクセス制御してみた(3.コンシューマーアカウント編)
「Redshiftの「データ共有」とAWS Lake Formationを利用して一元的にアクセスを制御してみた」シリーズの第3回目となります。前回の「2.ガバナンスアカウント編」に引き続き、「3.コンシューマーアカウント編」を解説していきます。ここでは、主にコンシューマーアカウントでの設定手順を紹介します。また、コンシューマーアカウント設定手順の後に、追加設定と手順に利用していたリソースのクリーンアップも記載してますので、ぜひ最後まで読んでいただければ幸いです。
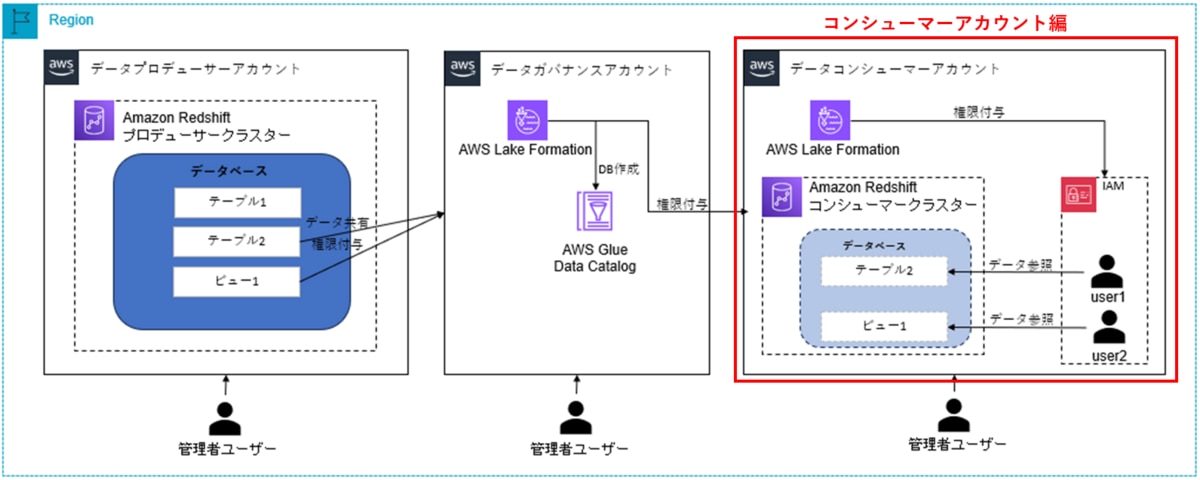
AWS Lake Formationで管理するRedshift「データ共有」機能の設定手順の流れ
- データプロデューサーアカウントでデータ共有作成(「1.プロデューサーアカウント編」)
プロデューサーアカウントの管理者ユーザーは、Amazon Redshift「データ共有」を作成します。その後、ガバナンスアカウントのデータカタログにアクセスを許可します。 - データガバナンスアカウントでDB作成及び権限設定(「2.ガバナンスアカウント編」)
ガバナンスアカウントの管理者ユーザーは、「データ共有」を受け入れます。「データ共有」に関連付けられたAmazon Redshiftデータベースを参照可能なAWS Glueデータベースを作成します。Lake Formationが管理できるようにAWS Glueデータベースおよびテーブル操作権限をコンシューマーアカウントに付与します。 - データコンシューマーアカウントで権限設定(「3.コンシューマーアカウント編」※本記事)
コンシューマーアカウントの管理者ユーザーは、AWS RAMを経由してリソース共有の招待を受け入れ、Lake Formationでアカウント内のIAMユーザーにきめ細かい権限を付与します。コンシューマークラスター内にDB及びユーザーを作成し、ユーザーに権限を付与します。 - データコンシューマーアカウントで動作確認(「3.コンシューマーアカウント編」※本記事)
IAMユーザーはコンシューマーアカウントにログインし、データセットにアクセスできることを確認します。
前提条件
コンシューマークラスターアカウントにおける前提条件
- 管理者ユーザーには、データレイク管理者権限とクラスター管理者権限を付与しています。
- テスト用のIAMユーザーには、Redshiftアクセス権限を付与しています。
設定手順
それでは、具体的な設定手順に入っていきます。
1. データコンシューマークラスターアカウント側の設定手順
AWSマネジメントコンソールに管理者ユーザーでサインインします。
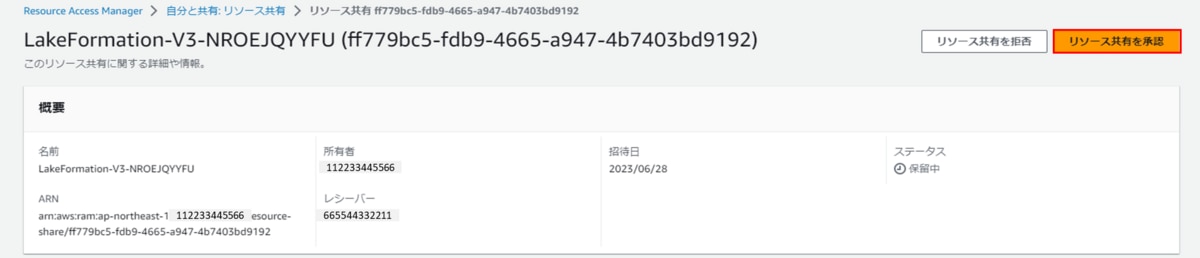
Resource Access Managerでリソース共有を受け入れます。
a. Resource Access Managerコンソール画面を開きます。
b. ナビゲーションペイン「リソースの共有」をクリックし、「自分と共有:リソース共有」画面で、ステータスが「保留中」のリソース共有が2通あることを確認できます。

c. それぞれの名前をクリックし、「リソース共有を承認」をクリックし、リソース共有を受け入れます。
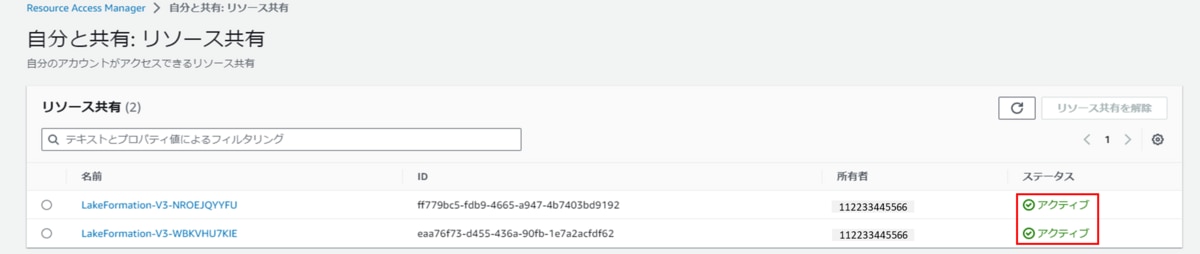
d. ステータスが「アクティブ」になっていることが確認できます。
- Lake FormationでIAMユーザー「consumer1」に権限を設定します。a. AWS Lake Formationコンソールを開きます。b. (オプション)Lake Formationコンソールに初めてログインする場合、設定画面が表示されます。「Add myself」を選択し、「Get started」をクリックします。c. ナビゲーションペイン「Data catalog」、「Databases」の順でクリックします。d. 「Databases」画面で、ガバナンスアカウントから共有されたDB「ticket_datashare」を選択し、「Actions」、「Grant」の順でクリックします。
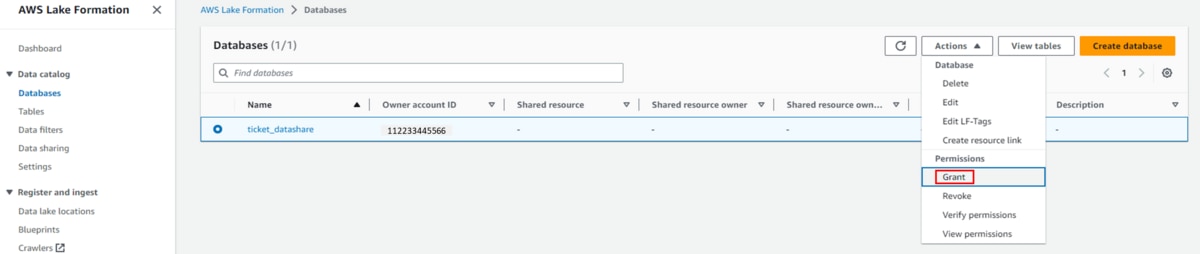
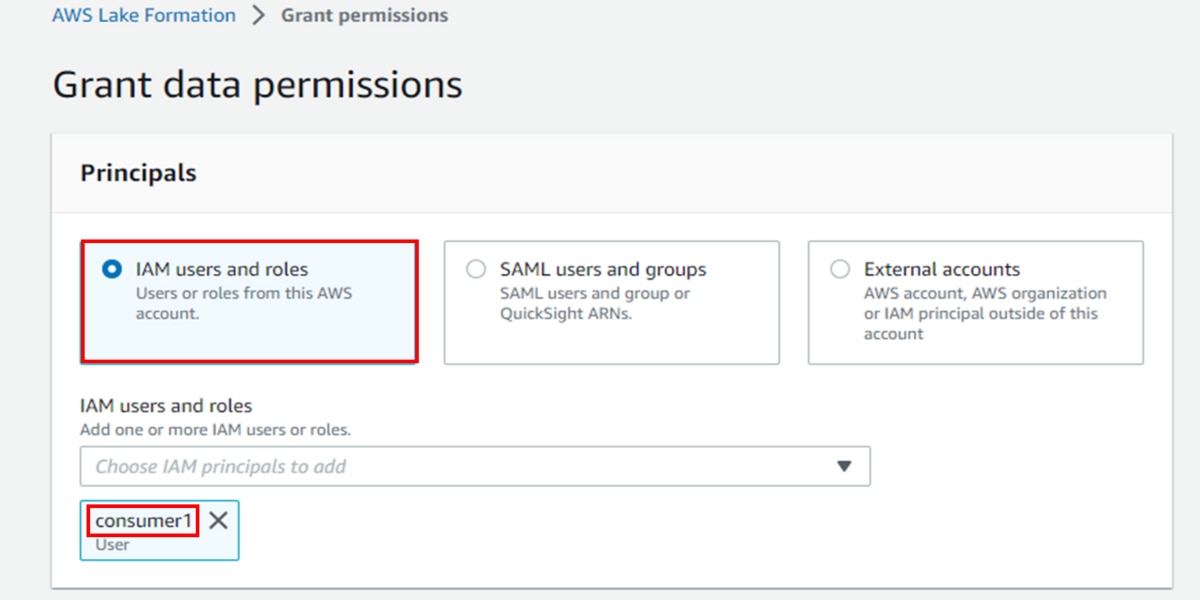
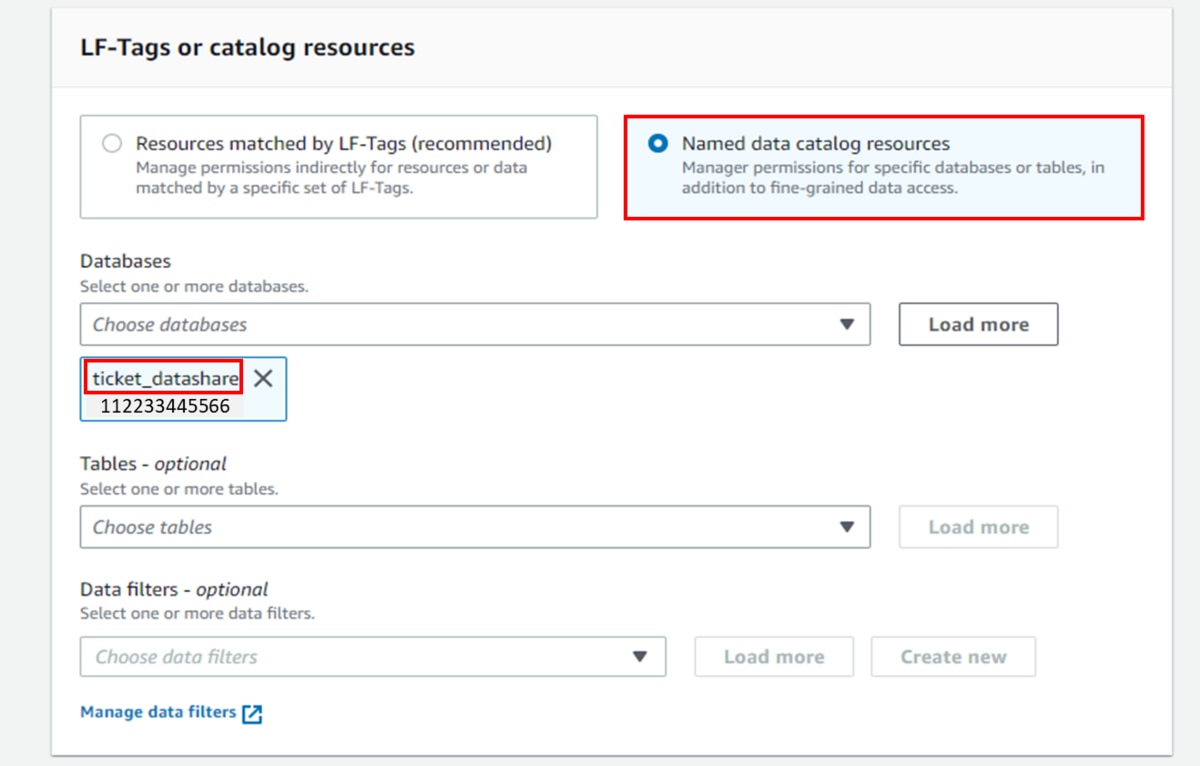
f. 「LF-Tags or catalog resources」に「Named data catalog resources」を選択し、「Databases」にデータベース「ticket_datashare」を選択します。
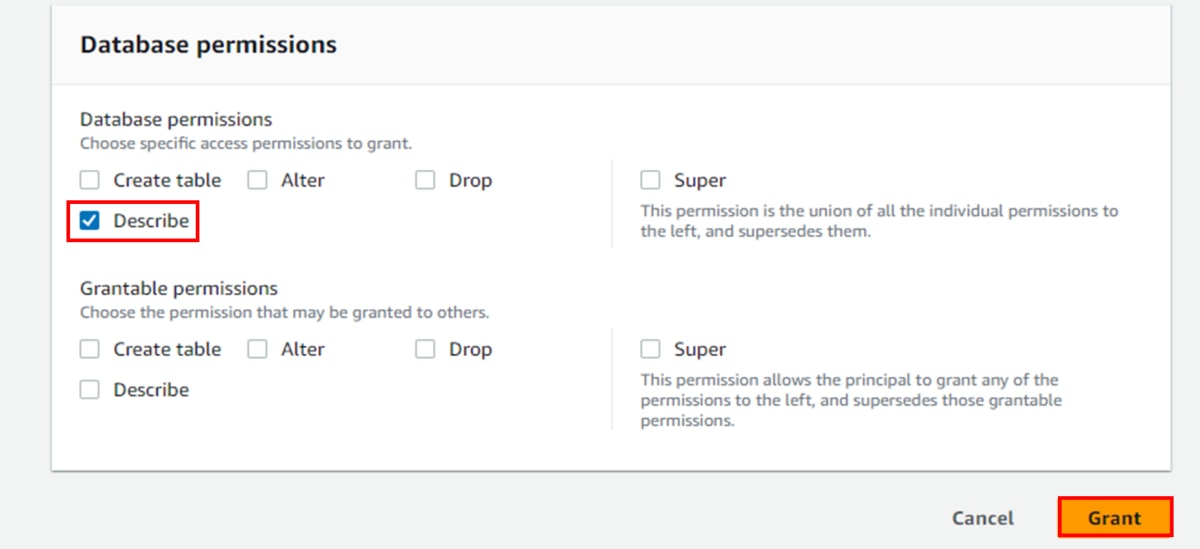
g. 「Database permissions」に「Describe」を選択し、「Grant」をクリックします。
h. 再度ナビゲーションペイン「Data catalog」、「Databases」の順でクリックします。
i. 「Databases」画面で、DB「ticket_datashare」を選択し、「アクション」、「Grant」の順でクリックします。
j. 「Grant data permissions」画面で、「Principals」に「IAM users and roles」選択し、対象のIAMユーザー「consumer1」を選択します。
k. 「LF-Tags or catalog resources」で「Named data catalog resources」を選択します。
「Databases」にデータベース「ticket_datashare」を選択します。「Tables」にテーブル「public.category_test」選択します。
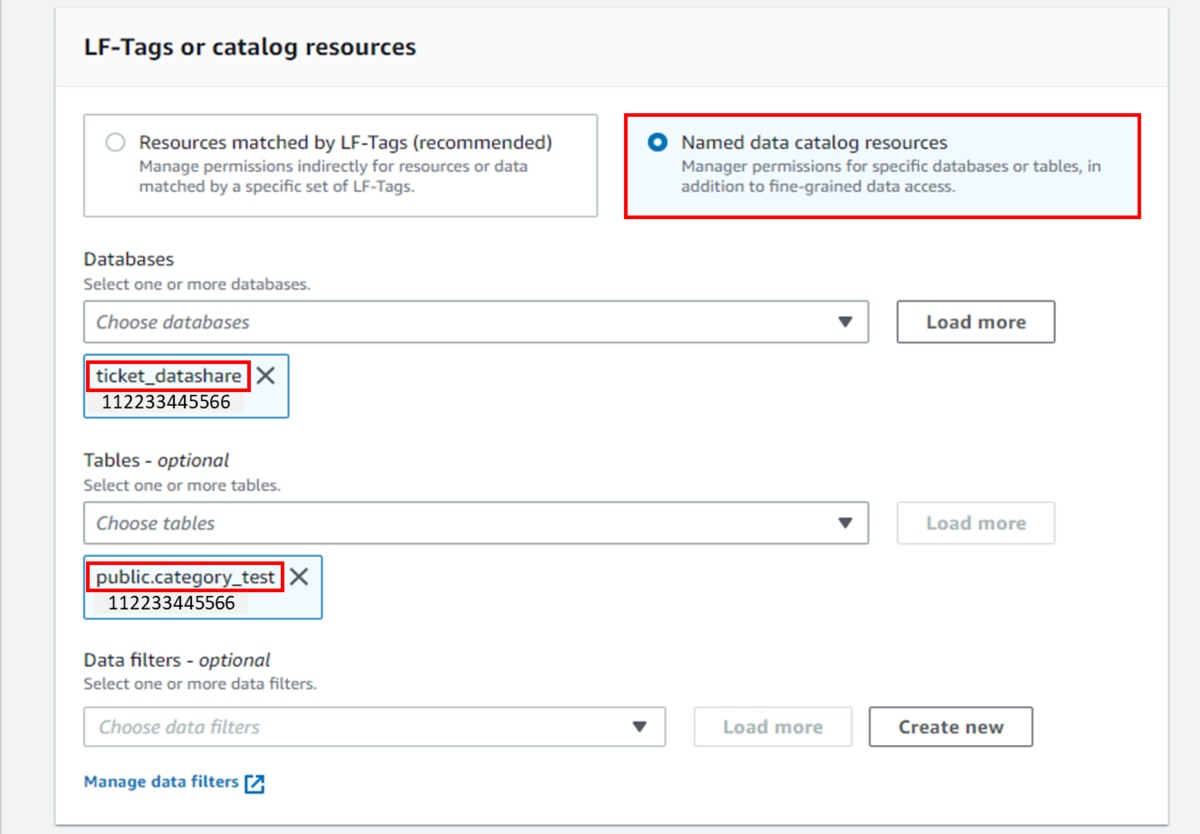
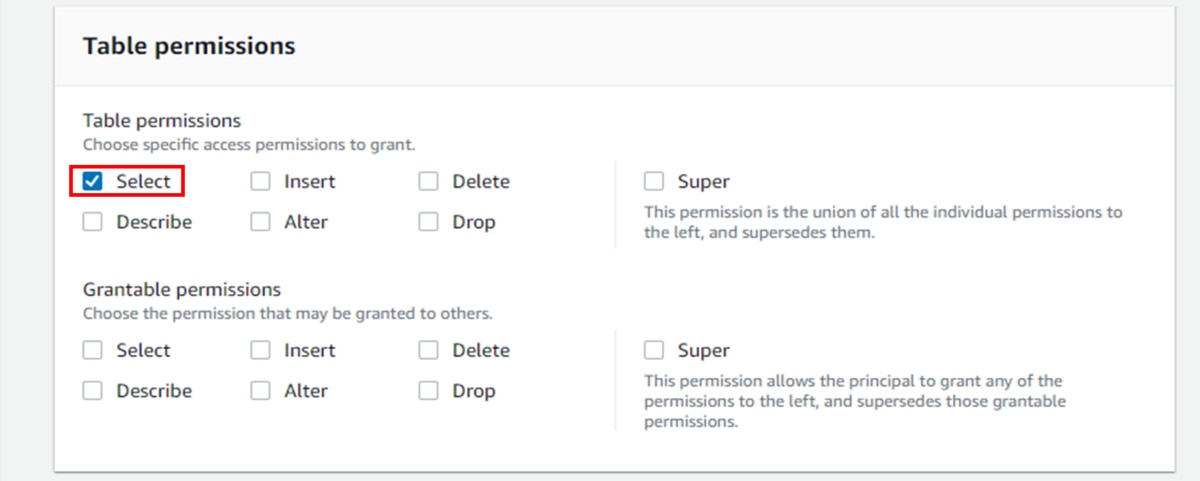
l. 「Table permissions」に「Select」を選択します。
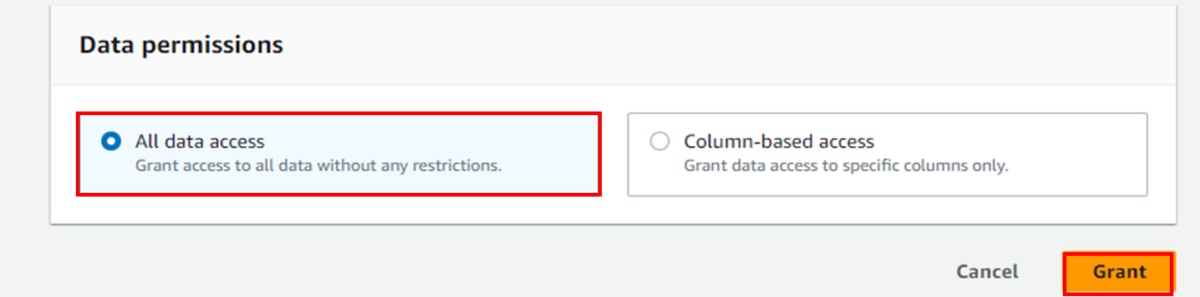
m. 「Data permissions」に「All data access」を選択し、「Grant」をクリックします。
- Lake FormationでIAMユーザー「consumer2」に権限を設定します。a. ナビゲーションペイン「Data catalog」、「Databases」の順でクリックします。b. 「Databases」画面で、ガバナンスアカウントから共有されたDB「ticket_datashare」を選択し、「アクション」、「Grant」の順でクリックします。c. 「Grant data permissions」画面で、「Principals」に「IAM users and roles」を選択し、対象のIAMユーザー「consumer2」を選択します。
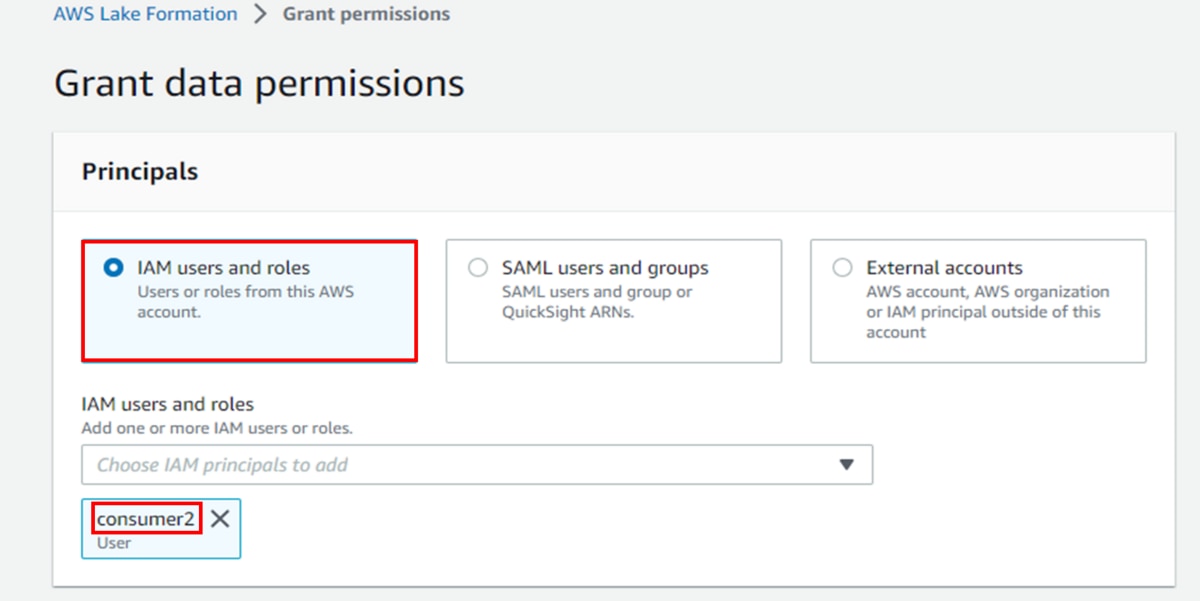
d. 「LF-Tags or catalog resources」に「Named data catalog resources」を選択し、「Databases」にデータベース「ticket_datashare」を選択します。
(※1.4~1.8までの手順は「consumer1」をご参照ください)
e. 「Database permissions」に「Describe」を選択し、「Grant」をクリックします。
f. 再度ナビゲーションペイン「Data catalog」、「Databases」の順でクリックします。
g. 「Databases」画面で、DB「ticket_datashare」」を選択し、「アクション」、「Grant」の順でクリックします。
h. 「Grant data permissions」画面で、「Principals」に「IAM users and roles」選択し、対象のIAMユーザー「consumer2」を選択します。
i. 「LF-Tags or catalog resources」で「Named data catalog resources」を選択します。
「Databases」にデータベース「ticket_datashare」を選択します。「Tables」にテーブル「public.sales_mv」選択します。
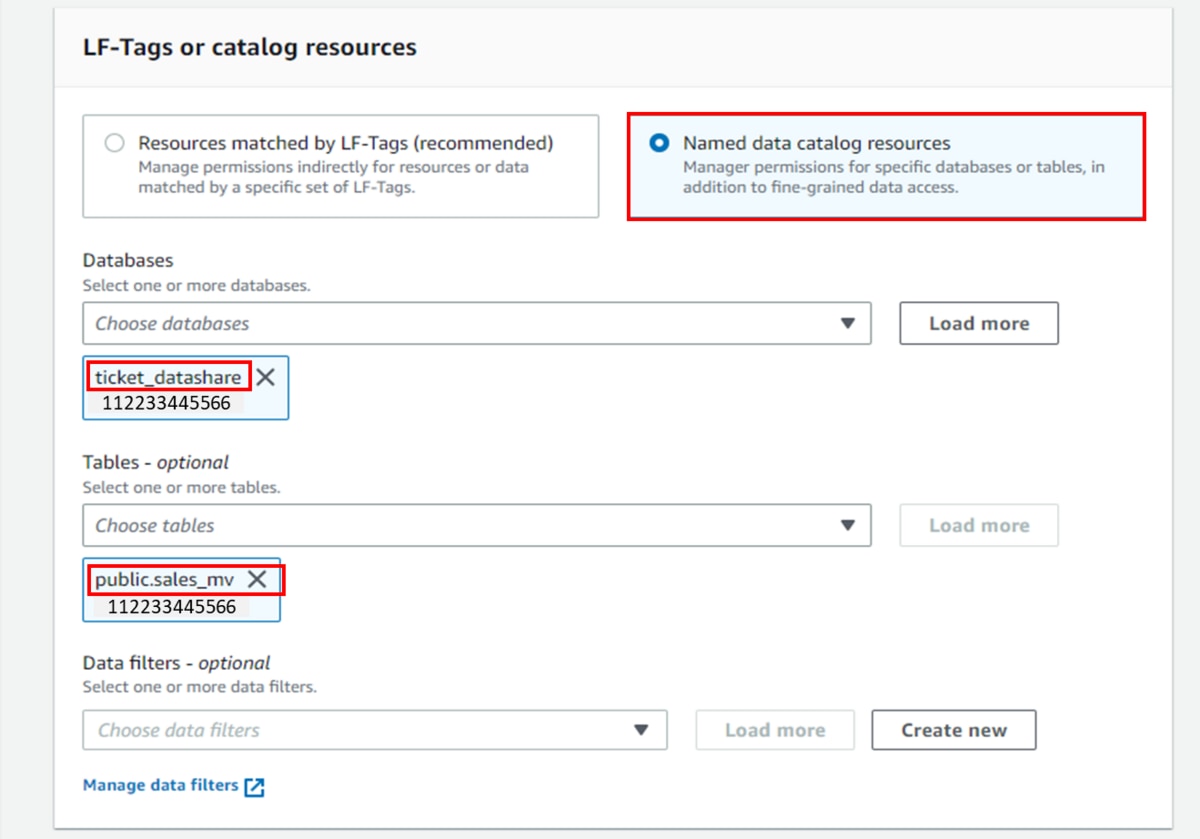
j. 「Table permissions」に「Select」を選択します。
k. 「Data permissions」に「Column-based access」、「Include columns」の順で選択します。
「Select columns」に共有するカラム「eventname」、「starttime」、「caldate」、「saletime」を選択し、「Grant」をクリックします。
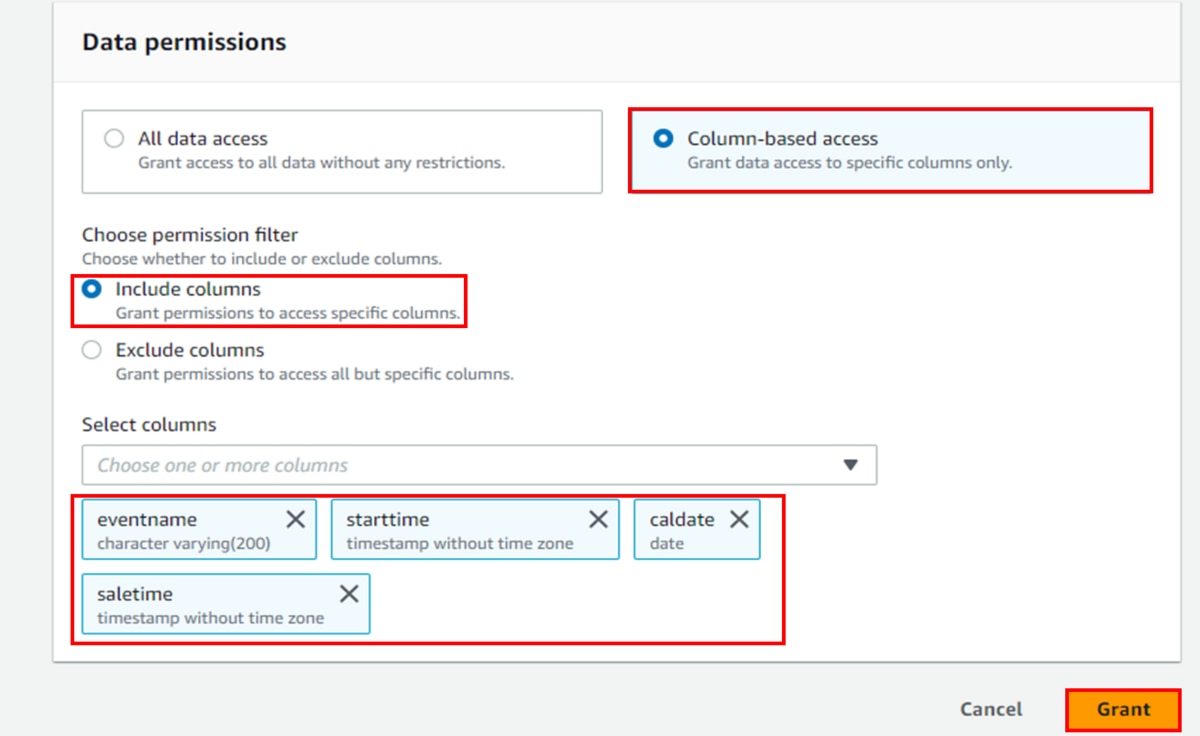
- 「Permissions」画面で、それぞれ権限が付与されることを確認できます。
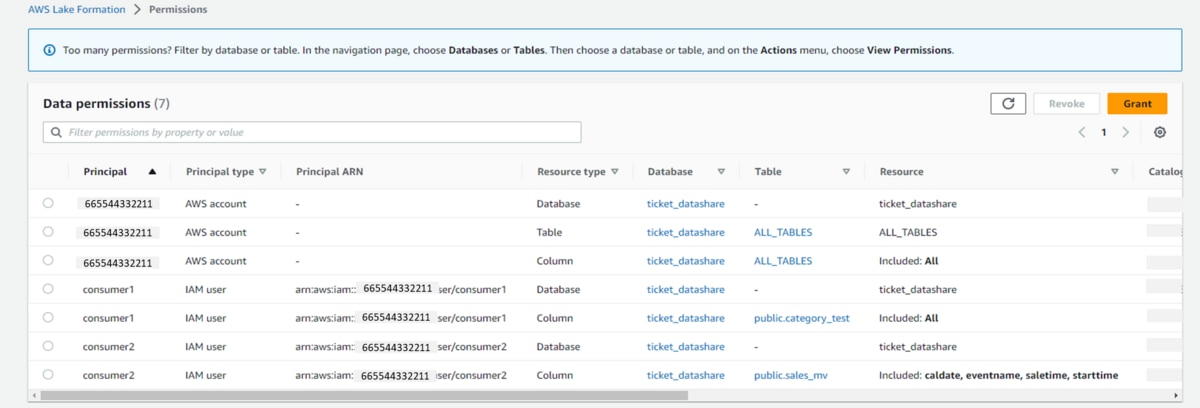
RedshiftクラスターからDBを作成し対象ユーザーに権限を付与します。
a. Amazon Redshiftコンソールを開き、ナビゲーションペイン「クエリエディタv2」をクリックします。
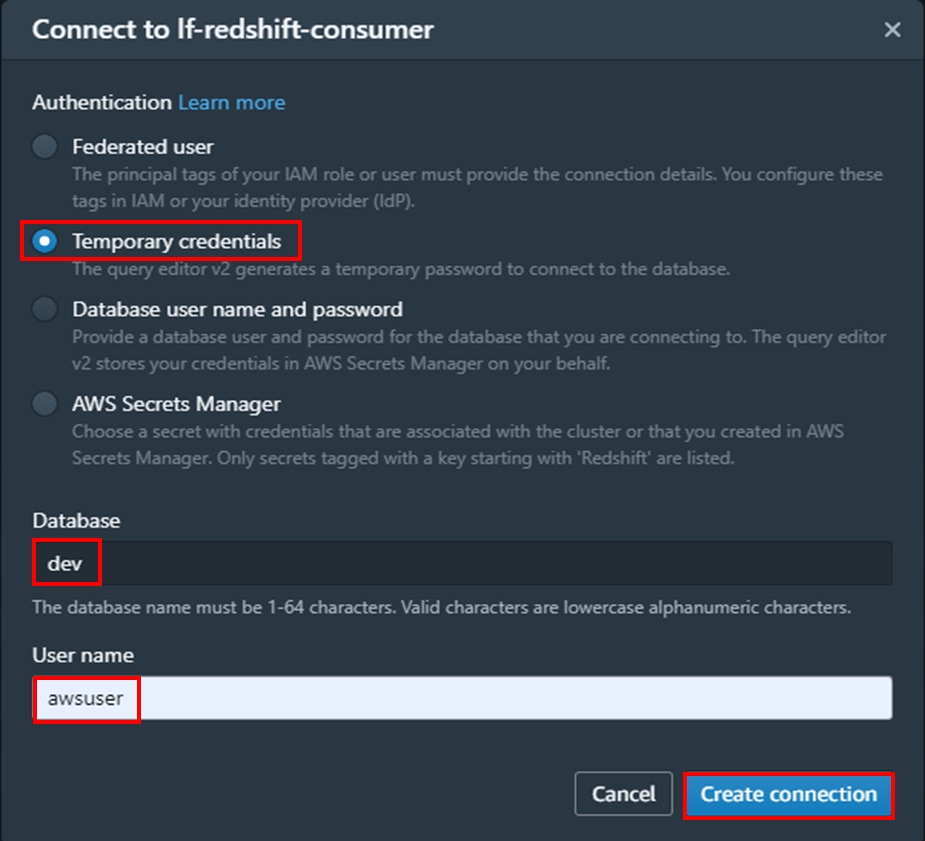
b. 対象のコンシューマークラスター「lf-redshift-consumer」を右クリックし、「Create connection」または「Edit connection」を選択します。

c. 「編集」ウインドウでは、「Authentication」に「Temporary credentials」を選択し、「Database」にデータベース「dev」、
「User name」にユーザー名「awsuser」を入力し、「Create connection」をクリックします。
d. 「クエリエディタ」ページでDB作成クエリを実行します。以下はサンプルクエリです。

CREATE DATABASE ticket_datashare
FROM ARN 'arn:aws:glue:<ガバナンスクラスターリージョン>:<ガバナンスアカウントID>:database/ticket_datashare'
WITH DATA CATALOG SCHEMA e. クエリエディタの内容をクリアして、次にユーザー作成のクエリとユーザー許可のクエリを実行します。以下はサンプルクエリです。

CREATE USER IAM:consumer1 password disable;
GRANT USAGE ON DATABASE ticket_datashare TO IAM:consumer1
CREATE USER IAM:consumer2 password disable;
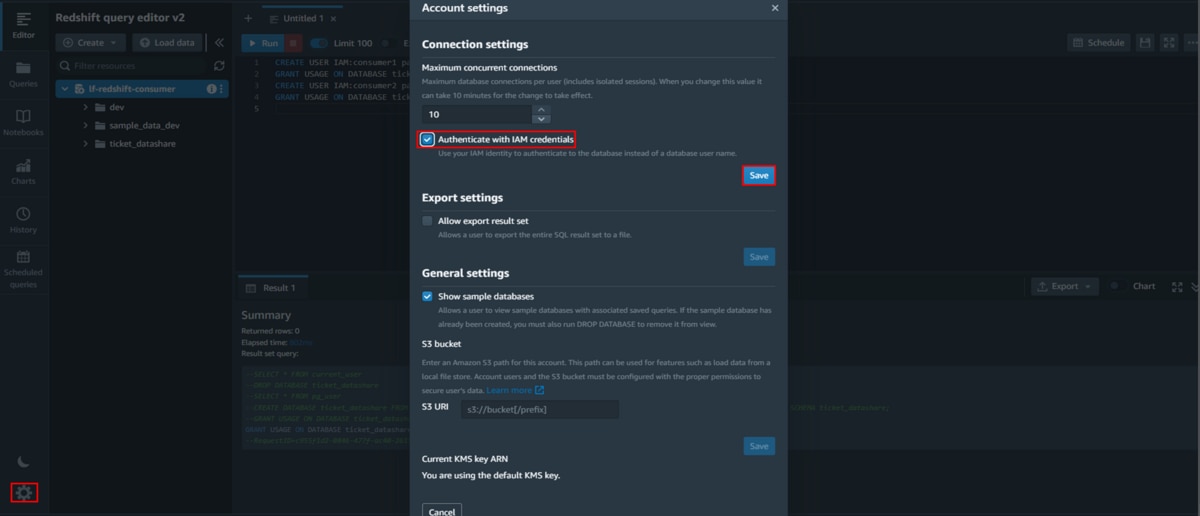
GRANT USAGE ON DATABASE ticket_datashare TO IAM:consumer2 f. 「クエリエディタv2」ページの左下にある設定アイコンをクリックして、「Account settings」ウインドウを開き、
「Authenticate with IAM credentials」にチェックを入れて、「Save」をクリックします。
- IAMユーザー「consumer1」からデータを抽出します。
a. AWSマネジメントコンソールにIAMユーザー「consumer1」でサインインします。
b. Amazon Redshiftコンソールを開きます。
c. ナビゲーションペインで[クエリエディター V2]を選択します。
d. 対象のコンシューマークラスター名「lf-redshift-consumer」を右クリックし、「Create connection」または「Edit connection」を選択します。
e. 「編集」ウインドウでは、「認証」で「Temporary credentials」を選択し、「Database」にデータベース名を入力し、「Save」をクリックします。
f. 「クエリエディタ」ページでカレントユーザー確認クエリを実行し、結果に「IAM:consumer1」が表示されることを確認します。以下はサンプルクエリです。
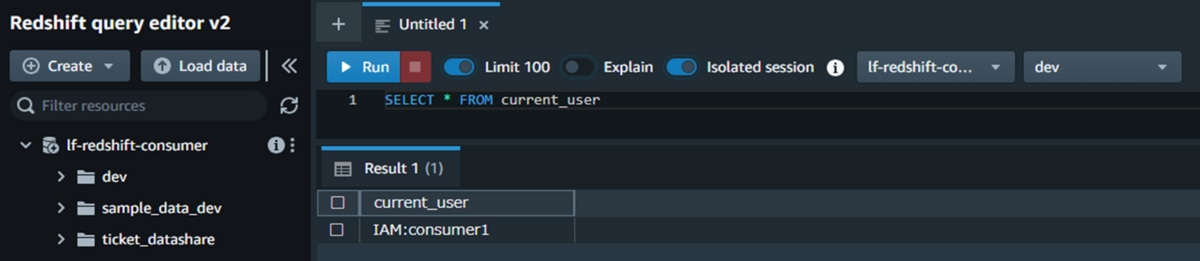
SELECT * FROM current_user g. IAMユーザーconsumer1に権限を付与したテーブル「category_test」に対して、データ抽出クエリを実行します。
対象データが抽出されることを確認できます。以下はサンプルクエリです。
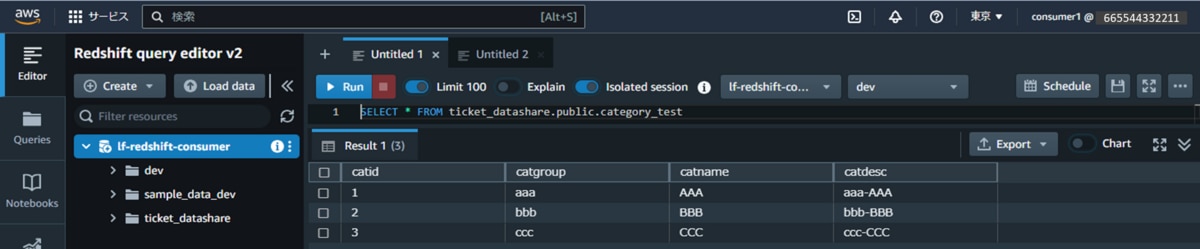
SELECT * FROM ticket_datashare.public.category_testh. 権限を付与していないビュー「sales_mv」に対して、データ抽出クエリを実行します。クエリ実行エラーが発生することを確認できます。
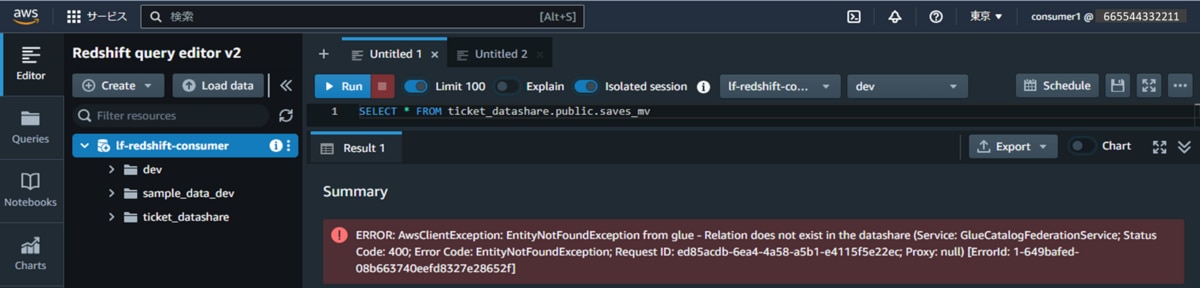
SELECT * FROM ticket_datashare.public.sales_mv- IAMユーザー「consumer2」からデータを抽出します。
a. AWSマネジメントコンソールにIAMユーザー「consumer2」でサインインします。
b. Amazon Redshiftコンソールを開きます。
c. ナビゲーションペインで[クエリエディター V2]を選択します。
d. 対象のコンシューマークラスター名「lf-redshift-consumer」に接続します。
e. 「クエリエディタ」ページにカレントユーザー確認クエリを実行し、結果に「IAM:consumer2」が表示されることを確認します。
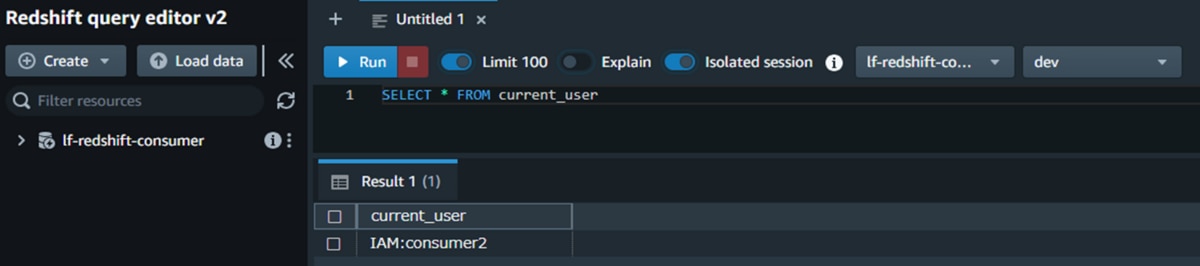
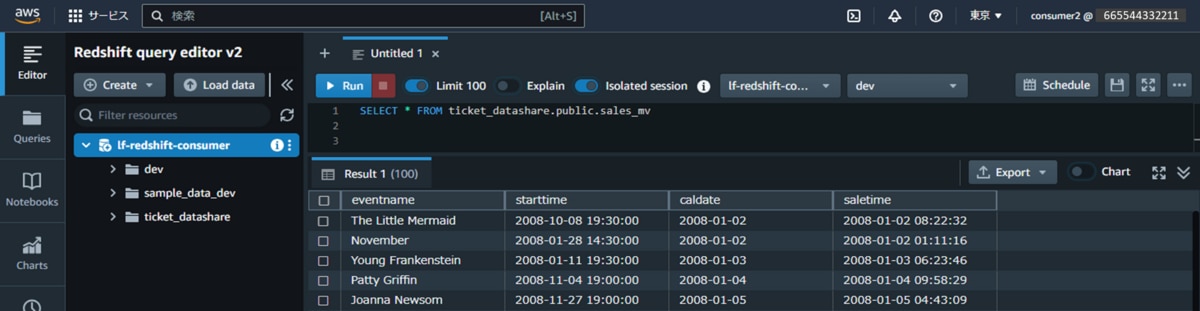
f. IAMユーザーconsumer2に権限を付与したビュー「sales_mv」に対して、データ抽出クエリを実行します。
対象データが抽出されることを確認できます。以下はサンプルクエリです。
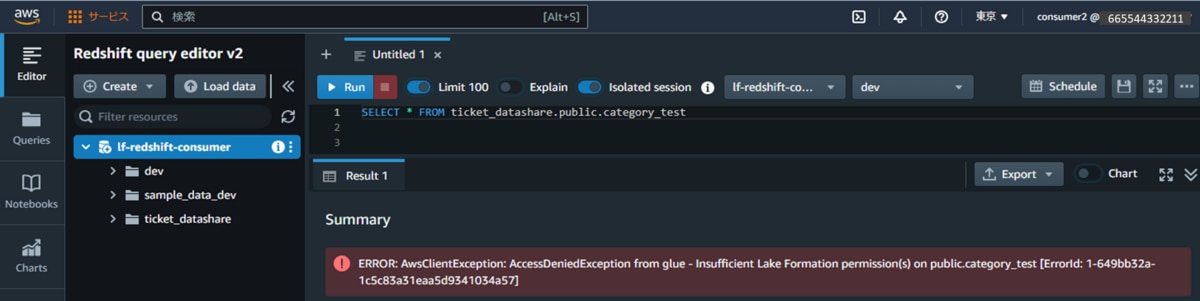
g. 権限を付与していないテーブル「category_test」に対して、データ抽出クエリを実行します。クエリ実行エラーが発生することを確認できます。
2. 追加設定(オプション)
プロデューサークラスターの対象テーブルにデータを追加し、コンシューマークラスターから新規追加されたデータが抽出されることを確認します。
プロデューサーアカウントの設定手順
a. AWSマネジメントコンソールに管理者ユーザーでサインインします。
b. Amazon Redshiftコンソールを開きます。
c. ナビゲーションペイン「クエリエディター V2」をクリックします。
d. 対象クラスター「lf- redshift-producer」に接続します。
e. データ新規追加SQLクエリを実行し、新規データが増えたことを確認できます。以下はサンプルクエリです。
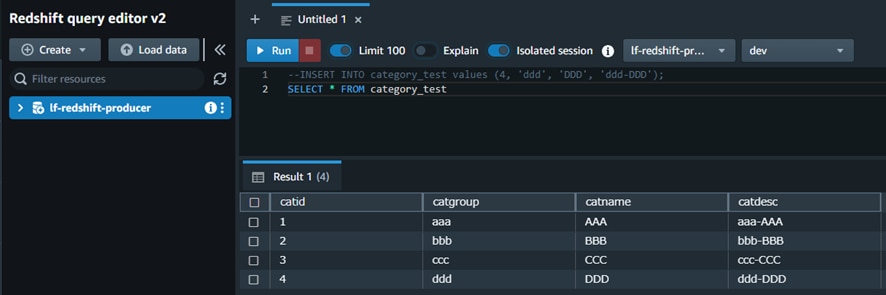
INSERT INTO category_test values (4, 'ddd', 'DDD', 'ddd-DDD');
SELECT * FROM category_testコンシューマーアカウントの確認手順
a. AWSマネジメントコンソールからIAMユーザー「consumer1」でサインインします。
b. Amazon Redshiftコンソールを開きます
c. ナビゲーションペイン「クエリエディター V2」をクリックします。
d. 対象クラスター「lf- redshift-consumer」に接続します。
e. IAMユーザーconsumer1に権限を付与したテーブル「category_test」に対して、データ抽出クエリを実行します。追加された対象データが抽出されることを確認できます。

SELECT * FROM ticket_datashare.public.category_test番外編(オプション)
リソースのクリーンアップ
- コンシューマーアカウントのクリーンアップ
a. Data lake permissionを削除(Revoke)します。
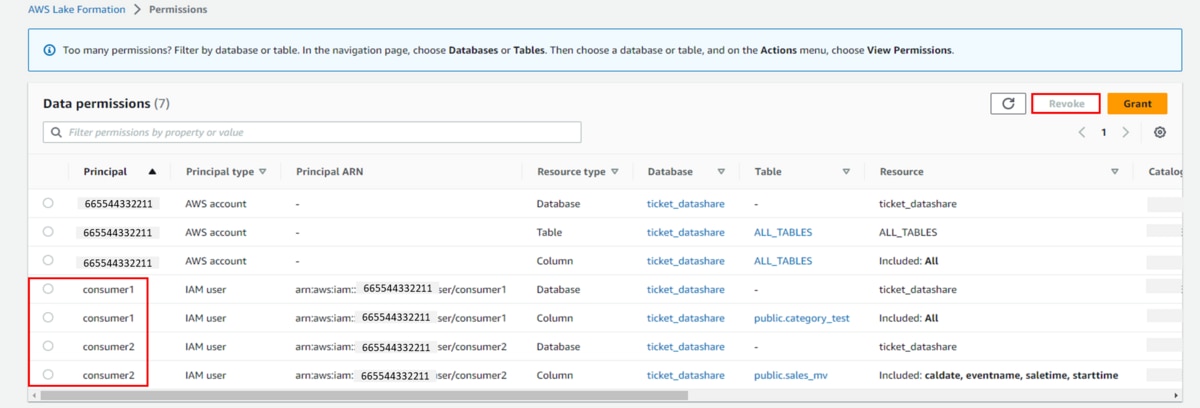
b. 作成したユーザー「consumer1」と「consumer2」を削除します。
c. Redshift「if-redshift-consumer」を削除します。
d. Redshift用に作成されたIAMロールを削除します。
- ガバナンスアカウントのクリーンアップa.Data lake permissionsを削除します。
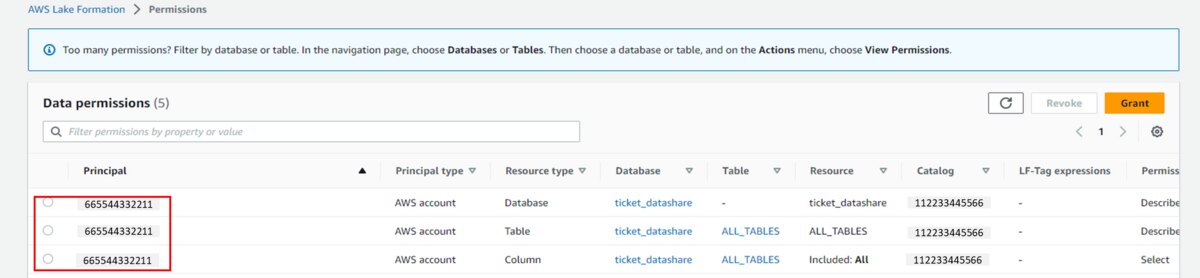
b. Databases→ticket_datashareを削除します。
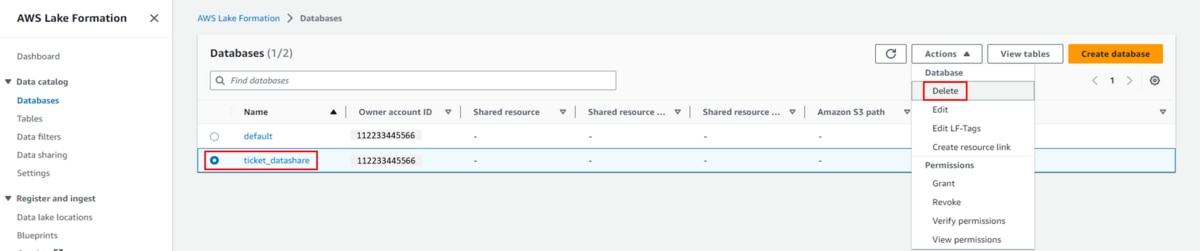
- プロデューサーアカウントのクリーンアップa. データ共有を削除します。
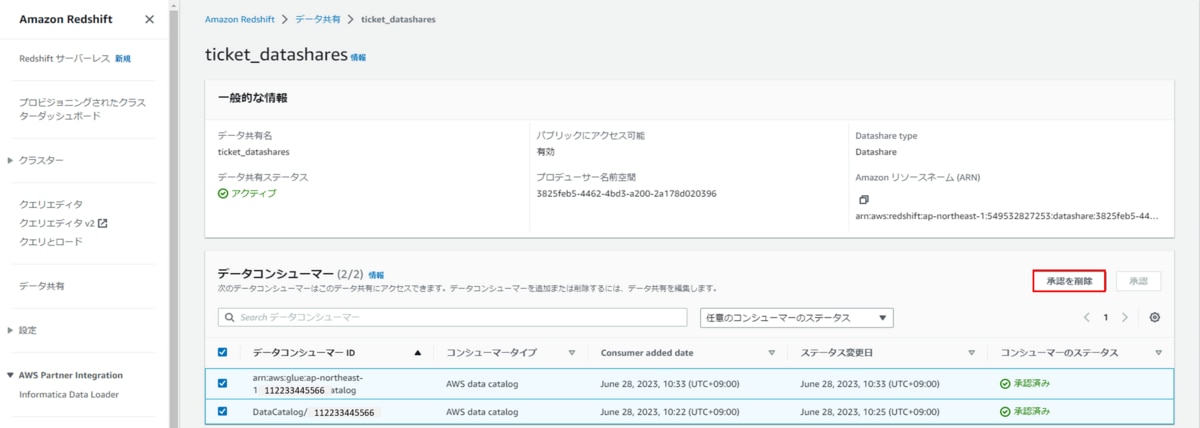
b. Redshift「If-redshift-producer」を削除します。
c. Redshift用のIAMロールを削除します。
最後に
最後までお読みいただきありがとうございます。
「1.プロデューサーアカウント編」、「2.ガバナンスアカウント編」、「3.コンシューマーアカウント編」3つのシリーズにわたってご説明いたしましたが、AWS Lake Formationによる一元管理のRedshiftデータ共有機能について、何となくイメージがつきましたか。
組織内でのデータ共有が必要な企業や複数のAWSアカウントでデータ共有を行う必要のある企業にとって、運用や管理が簡素化されるため重要な機能となります。今後、AWS Lake Formationによる一元管理のRedshiftデータ共有機能の需要が益々高まっていくと予想されます。
以上、「Redshiftの「データ共有」とAWS Lake Formationを利用して一元的にアクセスを制御してみた」でした!