
ハーネスエンジニアリング入門 ― AIエージェント時代の「開発の運転設計」とは ―
「AIに任せると作るのは速いのに、確認に時間がかかって、結局スピードが出ない」――生成AIを業務に取り入れた多くの現場で、こうした声が聞かれるようになりました。コードや文書を生み出すスピードは飛躍的に向上した一方で、その成果物を人間がレビューする工程が、新たなボトルネックになっているのです。実際にOpenAIは、エージェント主導の開発でコードの生成量が増えるほど、ボトルネックが人間のQA(品質保証)能力に移ったと報告しています。この課題への打ち手として、いま注目を集めているのが「ハーネスエンジニアリング」という考え方です。本記事では、ハーネスエンジニアリングとは何か、なぜ今必要とされるのか、そしてその土台を構成する要素までを、OpenAIとAnthropicの実践例をもとに分かりやすく解説します。
そもそも「ハーネス」とは何か
「ハーネス(harness)」はもともと馬具を指す言葉で、馬の力を制御し、暴れさせずに目的地まで進ませる道具を意味します。「大きな力はあるが、制御が必要」という点が、まさに今のAIと重なります。
AIの文脈でのハーネスとは、エージェントに与える入力データ、エージェントが使うツール、状態管理、評価、記録といった要素を束ね、AIを単なるモデルから「自律的に動くエージェント」として機能させる土台のことを指します。モデル単体はあくまで頭脳であり、それだけではエージェントとしては働きません。Anthropicも、モデルとハーネス(足場)を合わせて初めてエージェントとして評価すべきだと述べています。そして、このハーネスを人間が設計・開発することを「ハーネスエンジニアリング」と呼びます。「ハーネスエンジニアリング」という言葉が広く使われ始めたのはごく最近で、OpenAIが2026年2月に「ハーネスエンジニアリング:エージェントファーストの世界における Codex の活用 (Harness engineering: leveraging Codex in an agent-first world)」と題した記事を公開したことが、大きなきっかけになりました。
設計対象が「指示文」から「作業全体」へ広がった
ハーネスエンジニアリングは、AI活用における「設計対象」が段階的に広がってきた流れの先にあります。
生成AIが登場した当初に注目されたのは「プロンプトエンジニアリング」でした。これは、AIへの1回分の指示文をいかにうまく書くか、つまり「どう言えばうまく答えてくれるか」を追求する技術です。やがて、1回の指示文だけでは良い結果に導けない場面が増え、AIが推論するときに「何を・どの順番で・どれだけ見せるか」を設計する「コンテキストエンジニアリング」が重視されるようになります。Anthropicは、これをプロンプトエンジニアリングの自然な発展として位置づけています。
ハーネスエンジニアリングは、さらにその先にあります。コンテキスト管理はハーネス設計の中核論点の一つにすぎず、ハーネスエンジニアリングはそれに加えて、複数回の推論をどう動かすか、途中結果をどう評価するか、失敗時にどうやり直すか、次のセッションへ何を引き継ぐかまでを設計対象とします。指示文の書き方を磨くだけでは解けない問題が増えたことで、設計のスコープが「1回の応答」から「継続する作業全体」へと広がってきた、というわけです。

なぜ今、ハーネスエンジニアリングが必要なのか
ではなぜ今、ハーネスが必要とされるのでしょうか。背景には、ユーザーのPC上で自律的に動くAIエージェントの普及があります。こうしたエージェントは、コードを書いたり作業を進めたりするスピードが非常に速い一方で、出力された成果物を人間がレビューしたりQAでテストしたりする工程に時間が取られます。
この点について、OpenAIの報告は示唆的です。同社はエージェント主導の開発で、唯一の本当に希少な資源は「人間の時間と注意力」だと位置づけました。コードの生成量が増えるほど固定的な制約は人間のQA能力となり、そこがボトルネックになったのです。AIがいくら速く作業しても、人間がすべてを確認する前提のままでは、差し戻しや手戻りが累積し、トータルで見ると速くなりません。
そこでOpenAIは発想を転換し、レビュー作業のほぼすべてをエージェント間で処理する形へ移行しました。途中の検証はAIに行わせ、人間はプルリクエストをレビューすることもできますが、必須ではない――そういう運用にしたのです。Anthropicも、生成役と評価役を分けるループ(後述)が、ソフトウェア開発におけるコードレビューやQAに対応する構造だと整理しています。
どこまでをAIが自走し、どこだけを人間が見るかを先に設計する――そのために必要となる環境づくりが、ハーネスエンジニアリングなのです。

ハーネスを構成する4つの要素
OpenAIは前掲の記事で、Codexエージェント群に大規模ソフトウェア開発を任せるために、どんな環境を整えたかを具体的に説明しています。その内容は、おおきく4つの要素に整理できます。
①知識の置き場を整える
OpenAIがまず学んだのは、巨大な指示書を1枚用意しても失敗する、ということでした。すべてを詰め込んだ単一の指示ファイルは、コンテキストを圧迫し、何が重要か分からなくなり、すぐ陳腐化し、機械的なチェックも効きません。
そこで同社は、AIへの入口となるファイル(AGENTS.md)を百科事典ではなく「目次(約100行のマップ)」として扱い、詳細な知識は構造化した docs/ ディレクトリを正本(system of record)として管理しました。エージェントは短く安定した入口から始め、必要に応じて深い文書群へ案内される――この「段階的開示」によって、必要な情報だけを順にたどれるようになります。
②AIが自分で読める状態にする
OpenAIは「実行中にコンテキストからアクセスできないものは、事実上存在しないのと同じだ」と述べています。そこで同社は、Chrome DevTools Protocol(CDP)をエージェントのランタイムに組み込み、CodexがDOMスナップショットやスクリーンショットを扱い、画面を操作してバグを再現・検証できるようにしました。さらにログ・メトリクス・トレースも、各作業環境ごとのローカル観測スタック経由でエージェントが直接クエリできるようにしています。見えない情報は無いも同じだからこそ、UI・ログ・メトリクスをAIが直接読める場所へ移すわけです。
③生成→検証→修正のループを回す
OpenAIは、人間の役割が「コードを書くこと」から「環境を設計し、意図を明確にし、信頼できるフィードバックループを作ること」へ移ると説明しています。
実際の運用でも、エンジニアはタスクを渡して終わりにせず、Codexに自己レビュー・追加レビュー・フィードバック反映・再実行をループさせ、プルリクエストを完成へ近づけます。同社の環境では、1つのプロンプトから、現状確認・バグ再現・失敗の記録・修正・再検証・PR作成・レビュー応答・ビルド失敗の修復、そして判断が必要なときだけ人間へのエスカレーション、最後にマージまでを進められるようになりました。出力をもらって終わりにせず、検証とやり直しまで含めて作業を閉じる――これがハーネスエンジニアリングの最大の肝です。
④原則を機械的に強制し、継続的に掃除する
検証には基準が必要です。OpenAIは、各ドメインを固定されたレイヤー構造に分け、依存の向きを厳密に制限するアーキテクチャを、カスタムリンターと構造テストで機械的に強制しました。
こうしたルールは、人間中心のワークフローでは細かい制約に感じられても、エージェントにとっては「増幅器」として働き、一度エンコードすればあらゆる場所に同時適用されます。加えて、エージェント生成コードは放置すると徐々に荒れていくため、当初は人間が毎週金曜(稼働の約2割)を「動くが荒れたコード」の掃除に費やしていました。それではスケールしないと判断し、機械的に判定できる明確なルール(golden principles)をリポジトリに埋め込み、バックグラウンドのCodexタスクが逸脱を検出して品質評価を更新し、リファクタリング用のPRを自動で開く方式へ切り替えています。
これら4つのいずれかが欠けると、「速いだけで荒れたAIコード」が積み上がってしまいます。

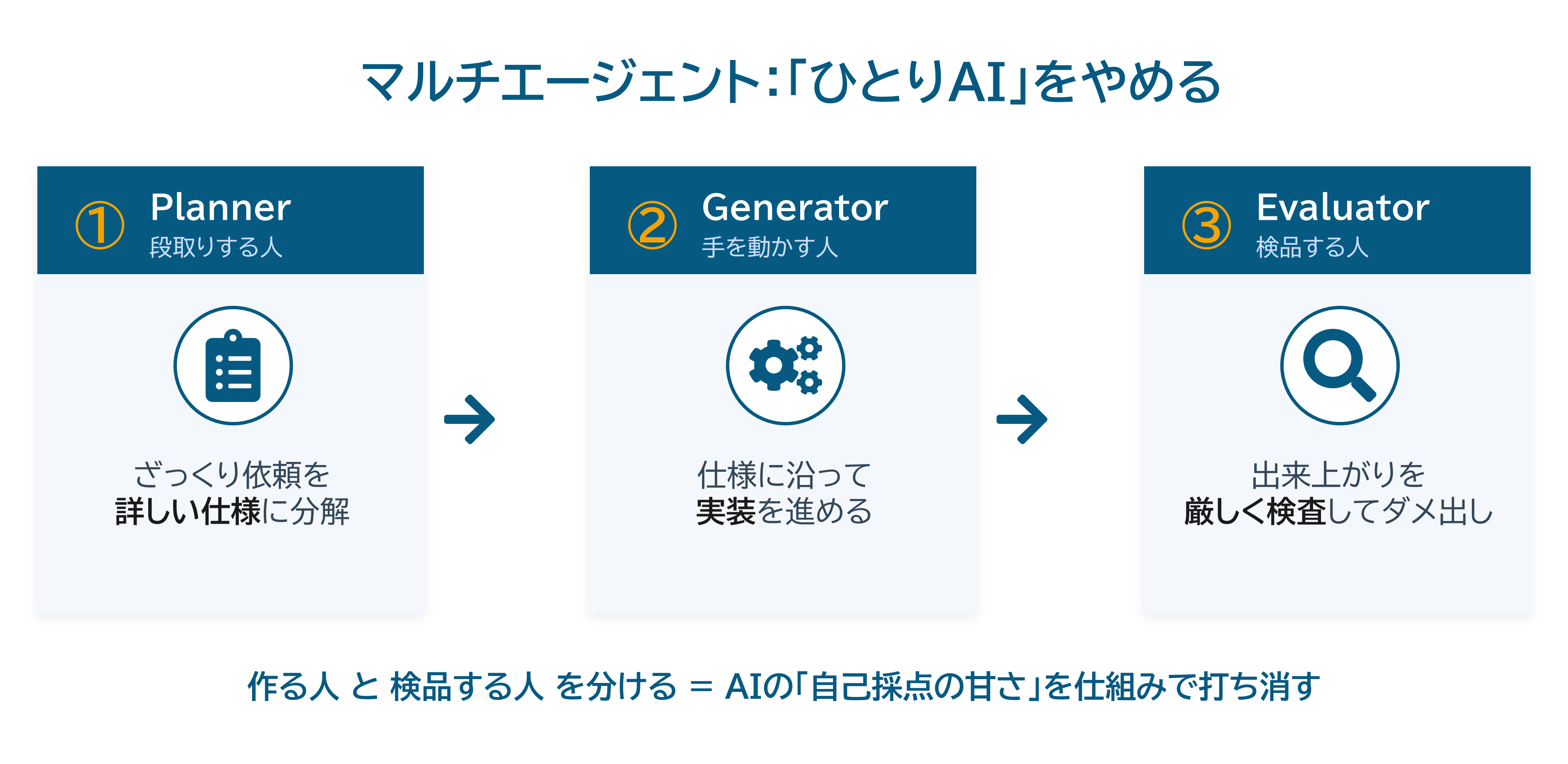
マルチエージェント:「ひとりAI」をやめる
4要素の中でも特に重要な「生成→検証→修正のループ」について、Anthropicは複数のエージェントで役割を分ける「マルチエージェント化」を有効な手段として示しています。
その出発点にあるのは、AIは自分の成果物の評価が甘くなりやすい、という観察です。自分が作ったものを自分で採点させると、品質が低くても無難に褒めてしまう傾向がある。そこで役割を分けます。ざっくりした依頼を詳しい仕様へ分解する計画役(Planner)、仕様に沿って実装を進める生成役(Generator)、出来上がりを要件・テスト・品質基準に照らして厳しく検査する評価役(Evaluator)の3つです。作る主体と検品する主体を分けることで、自己採点の甘さを仕組みで打ち消すわけです。
事例:ハーネスの効果はどれくらいか
ハーネスの効果はどれほどのものなのでしょうか。Anthropicは「ハーネスあり / なし」を比較した実験を公開しています。使用したモデルはいずれもClaude Opus 4.5です。
「レベルエディタやスプライトエディタ、プレイ可能なテストモードを備えた2Dレトロゲームメーカーを作って」という同一の指示に対し、単体のAI(ハーネスなし)は20分・約9ドルで成果物を出しましたが、見た目は整っていてもゲームは動かず、入力に反応せず操作できない、「それっぽいけれど使えない」ものでした。一方、計画役・生成役・評価役による3エージェントのハーネス版は6時間・約200ドルとコストは約20倍かかったものの、評価役が多数の実バグを検出しながら作り込み、ゲームはきちんと動き、直感的に操作できる「本当に使えるアプリ」に仕上がりました。コストは増えても、成果物の質はまったくの別物だったのです。
まとめ
ハーネスエンジニアリングとは、AIに「うまく指示する」技術ではなく、AIが安定して自走する環境そのものを設計・開発する技術です。OpenAIの実践が示すように、ソフトウェアづくりに規律が必要なことは変わりませんが、その規律はコードそのものよりも、コードを取り巻くスキャフォールディング(足場)に現れるようになりました。
ボトルネックは「生成」ではなく「検証」へ移りました。知識の置き場を整え、AIが読める状態をつくり、生成から検証・修正までのループを回し、原則を機械的に強制する。そして必要に応じて、生成・評価の役割を分けたマルチエージェントで自己評価の甘さを打ち消す。こうした環境を整えられるかどうかが、これからの開発を左右します。良いモデルを選ぶこと以上に、良い「走らせ方」を設計できるかが競争力を決める時代になっているのです。


