
AWS DEA実践シリーズ③ ビッグデータ・ストリーミング処理サービス | EMR、MWAA、Managed Service for Apache Flink・MSK
AWS DEA実践シリーズの最終回の今回は、ビッグデータやストリーミング処理において重要な「EMR」「Managed Workflows for Apache Airflow(MWAA)」「Managed Service for Apache Flink」「Amazon MSK(Managed Streaming for Apache Kafka)」について、それぞれの特徴とAWS上での役割を解説します。また、ワークフロー管理サービスの比較などもご紹介します。
目次[非表示]
- 1.Amazon EMR | クラスタサービス
- 2.Amazon Managed Workflows for Apache Airflow(MWAA) | Airflowサービス
- 3.Amazon Managed Service for Apache Flink | Flinkサービス
- 4.Amazon MSK(Managed Streaming for Apache Kafka)| Kafkaサービス
- 5.Apache Kafka・Flink・AirflowとAWSのワークフロー管理サービスの違いと使い分け
Amazon EMR | クラスタサービス

Amazon EMRは、大規模データのETL処理や分散データ分析を実現するフルマネージド型クラスタサービスです。Apache Spark、Hadoop、Hive、Prestoなどのオープンソース分析フレームワークをAWS上で簡単に利用できます。
<主な特徴>
- 大規模データの高速処理数TB~PB級のデータを分散並列処理。Glueよりも大規模なデータセットに最適。
- コスト効率スポットインスタンスや自動スケールでコスト最適化。大規模ジョブでもコストパフォーマンスが高い。
- 柔軟なフレームワーク選択Spark、Hadoop、Hive、Presto、HBaseなど、多様なOSSを選択・組み合わせ可能。
<ユースケース例>
- ビッグデータの集計・変換・機械学習
- データウェアハウスの構築やデータマート作成
- WebログやIoTデータのバッチ分析
<Glueとの使い分け>
- Glue:小規模~中規模データのノーコード/ローコードETLに最適
- EMR:大規模データや複雑な分散処理、カスタム分析に最適
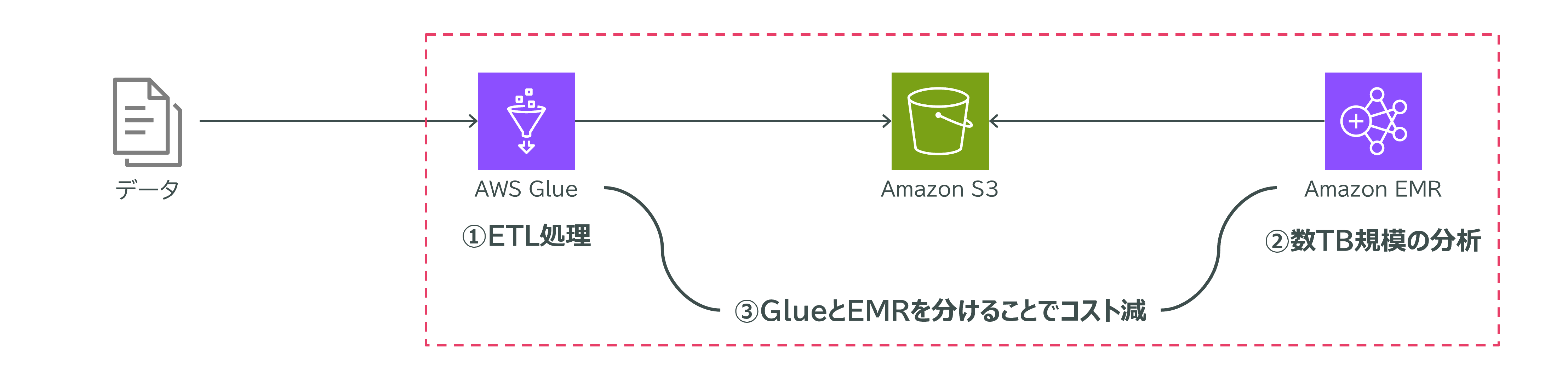
ユースケース:GlueとEMRを使った大規模データ分析の効率化
ある企業では、マーケティング施策の改善を目的に、ユーザーアンケート結果や行動ログを分析しています。これらのデータはAmazon S3に保存されており、すでに数テラバイト規模のデータが蓄積されています。さらに、毎日約100GBの新しいデータが追加されます。
この企業の要件は以下の通りです:
- 新しく追加されるデータには「形式の正規化や不要項目の除外」などの前処理が必要。
- 分析チームは、過去データも含めた全データを対象に定期的な分析処理を実行したい。
- 運用コストを抑えつつ、それぞれの処理に適したAWSサービスを選択したい。
解決方法
- 新規データの前処理(ETL)にはAWS Glueジョブを使用Glueは軽量な前処理や定型的なデータ整形に向いており、コスト効率も高いです。
- 全データの分析にはAmazon EMRを使用EMRは数テラバイト規模の大規模・複雑な分析処理に最適です。
ポイント
- GlueとEMRを使い分けることで、運用コストを抑えつつ、効率的にデータ処理・分析が可能です。
- GlueでETL処理を行い、S3に保存した後、EMRで定期的に大規模データの分析を実施します。
このように、GlueとEMRを適切に使い分けることで、大量データの前処理と分析を効率よく運用できます。
Amazon Managed Workflows for Apache Airflow(MWAA) | Airflowサービス

Amazon Managed Workflows for Apache Airflow(MWAA)は、ワークフロー管理・スケジューリングのためのフルマネージド型Apache Airflowサービスです。データパイプラインやバッチジョブの依存関係・実行順序・スケジュール管理をPythonコードで定義できます。
<主な特徴>
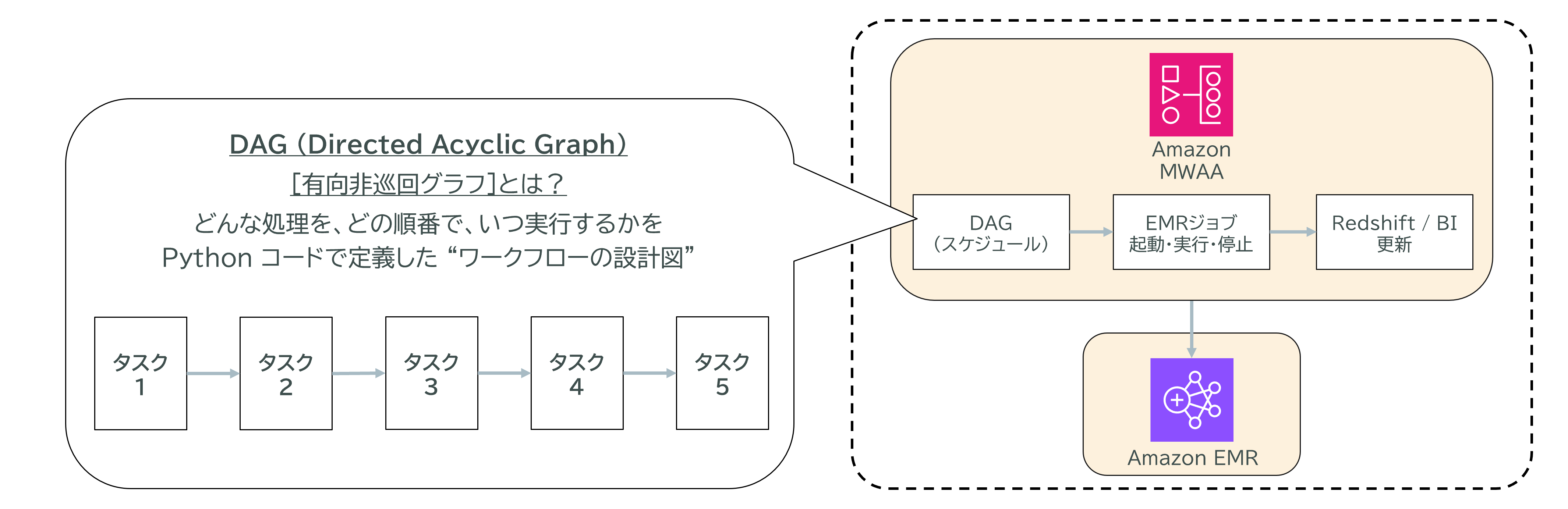
- DAG*(有向非巡回グラフ)によるワークフロー設計各処理(タスク)やその依存関係、実行順序をDAGとしてPythonで記述。
- スケジューリング・監視・リトライ定期実行や失敗時の自動再実行、進捗・エラー監視も管理画面から容易に確認。
- AWSサービス連携EMRやRedshift、Lambda、S3などのAWSリソースをAirflowタスクとして連携可能。
*DAG (Directed Acyclic Graph):有向非巡回グラフ。どんな処理を、どの順番で、いつ実行するかをPython コードで定義した、ワークフローの設計図
<ユースケース例>
- ETLパイプライン全体の自動化
- データ処理の依存関係管理
- マルチステップのバッチ処理や分析ワークフロー
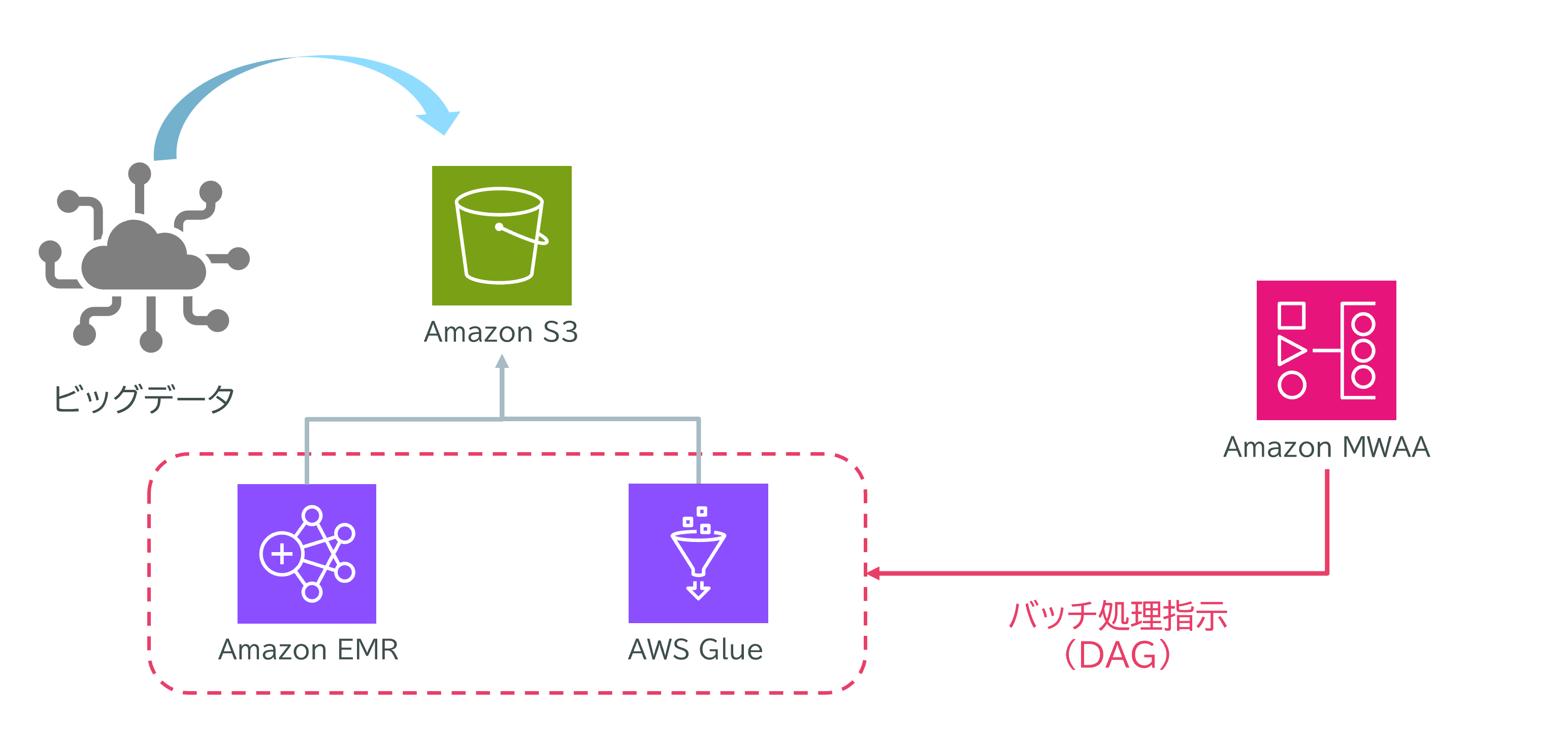
ユースケース:MWAA・Glue・EMRによるデータレイクの効率的な分析基盤
あるAI系スタートアップ企業では、Amazon S3を基盤としたデータレイクに大量の顧客調査データを蓄積しています。S3にはすでに数テラバイト規模のデータが保存されており、毎日100GBの新しいデータが追加・更新されています。
この企業の課題は、
- 新規データに対してETL処理(形式の統一や不要項目の除去)を行いたい
- 全てのデータを対象に機械学習による分析を定期的に実行したい
- これらをコスト効率良く、運用負担を抑えて管理したい
- という点です。
解決方法
- 新規データのETL処理はAWS Glueジョブで実行Glueはサーバーレスで、毎日追加される大量データの前処理を効率よく実施できます。
- 全データの分析はAmazon EMRで実施EMRはテラバイト級のデータを分散処理し、機械学習分析もスケーラブルに対応できます。
- Amazon MWAA(Airflow)のDAGでGlueとEMRのジョブをオーケストレーションAirflowのDAG(ワークフロー設計図)を使い、GlueとEMRのジョブを自動スケジューリング。必要なタイミングでバッチ処理を実行できます。
ポイント
- GlueとEMRを組み合わせて使い分けることで、コスト効率が高く、大量データの前処理と分析がスムーズに実現できます。
- MWAAでワークフローを管理することで、運用負担を最小限に抑え、自動化・定期実行が可能です。
このように、Amazon MWAA(Airflow)でGlueとEMRのジョブをスケジューリングする構成は、大量データのETL処理と分析を効率よく自動化し、コストも抑えられる最適なユースケースとなります。
Amazon Managed Service for Apache Flink | Flinkサービス

Managed Service for Apache Flinkは、ストリーミングデータのリアルタイム処理・分析を実現するフルマネージドサービスです。Apache Flinkは、ストリームデータの複雑な変換・集計・異常検知などを高パフォーマンスで実行できる分散処理エンジンです。
<主な特徴>
- リアルタイムストリーム処理秒間数千~数百万件規模のデータをリアルタイムに集計・変換・フィルタリング。
- 異常検知やセッション分析しきい値やパターン検出によるリアルタイムアラート(SNS通知等)やセッション集計も可能。
- スケーラビリティ・高可用性自動スケールや障害時の自動復旧で、安定したリアルタイム分析基盤を構築。
<ユースケース>
- IoTセンサーやアプリイベントのリアルタイム集計
- 不正アクセスや障害の即時検知
- ストリームデータの加工・フィルタリング後のS3やRedshiftへの保存
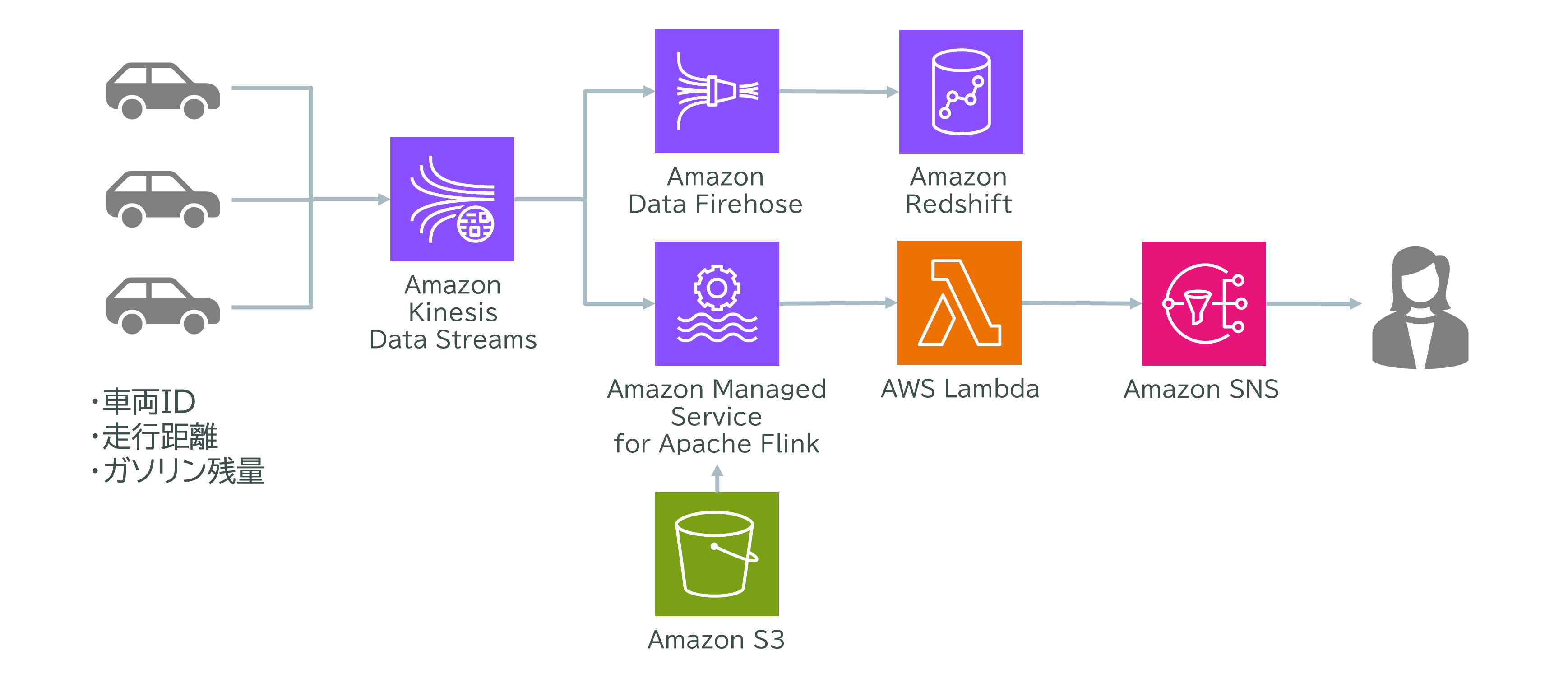
ユースケース:Kinesis Data Streams・Flink・Redshift・Lambda・SNSによる配送車両データのリアルタイム監視と通知
ある配送会社では、全国の配送車両から車両ID、走行距離、配達情報などのデータをKinesis Data Streamsでリアルタイムに収集しています。車両データはAmazon Redshiftに保存され、データエンジニアがほぼリアルタイムでレポートを作成しています。
さらに、特定の車両のガソリン残量があらかじめ設定した閾値を下回った場合、運用担当者に即時通知したいという要件もあります。車両データや閾値データはAmazon S3に保存されています。
解決方法
- Kinesis Data Streamsで配送車両からのデータをリアルタイム収集
- Amazon Data Firehoseを使って、ストリームデータをAmazon Redshiftにロード
- 同じストリームデータをAmazon Managed Service for Apache Flinkに入力
- FlinkでS3上の閾値データとリアルタイムで比較し、ガソリン残量が閾値を下回った場合はAWS Lambdaを起動
- LambdaがAmazon SNSを使って運用担当者に即時通知
ポイント
- Kinesis Data StreamsとFlinkの組み合わせで、リアルタイムなデータ処理・判定が可能
- Data FirehoseでRedshiftへ自動ロードし、分析やレポート作成を効率化
- Lambda+SNSで、閾値下回り時に即座に担当者へ通知
この構成により、配送車両の状態をリアルタイムで監視し、ガソリン残量などの異常があれば即時に運用担当者へ通知できる、効率的で運用負荷の低い仕組みを実現できます。
Amazon MSK(Managed Streaming for Apache Kafka)| Kafkaサービス

Amazon MSK(Managed Streaming for Apache Kafka)は、Apache Kafkaをフルマネージドで利用できるAWSのサービスです。Kafkaは、分散型の高スループットなメッセージング基盤として世界中で広く使われています。Amazon MSKを利用することで、インフラの構築や運用・スケーリング・障害対応などをAWSが自動で管理し、ユーザーはKafkaのセットアップや運用負荷を大きく軽減できます。
<主な特徴>
- フルマネージド:クラスタのプロビジョニング、パッチ適用、監視、障害復旧などをAWSが自動化。運用負担を大幅に削減。
- 高可用性・耐障害性:マルチAZ配置や自動バックアップ、データのレプリケーションによる高い可用性。
- セキュリティ:VPC内配置、暗号化(転送時・保存時)、IAM連携、アクセスコントロールなどエンタープライズ要件にも対応。
- スケーラビリティ:トラフィック増加時もブローカーやストレージの拡張が容易。
- Kafkaエコシステム互換:オープンソースKafkaと互換性が高く、既存のKafkaクライアントやツールをそのまま利用可能。
<ユースケース>
- リアルタイムデータパイプライン:アプリケーションログ、IoTデバイスデータ、クリックストリームなどの大量イベントを低遅延で収集・分配。
- マイクロサービス間の非同期連携:サービス間の疎結合なイベント駆動型アーキテクチャの基盤として活用。
- データレイクや分析基盤への連携:ストリーミングデータをS3やRedshift、Elasticsearch、Flinkなど他の分析サービスへ柔軟に連携。
- 異常検知やリアルタイム分析:FlinkやSpark Streamingと連携し、リアルタイムでデータ集計やアラート検知を実現。
Amazon MSKは、Kafkaのメリットをそのままに、AWSの運用自動化・高可用性・セキュリティを組み合わせた、企業のストリーミング基盤構築に最適なサービスです。
Apache Kafka・Flink・AirflowとAWSのワークフロー管理サービスの違いと使い分け
今回の勉強会では、「Apache Kafka」「Apache Flink」「Apache Airflow」の3つのOSS(オープンソースソフトウェア)サービスが登場しました。
OSS(オープンソースソフトウェア)とAWSマネージドサービスの違い
もともとApache Spark、Airflow、FlinkなどはOSSとしてオンプレミス環境でも利用可能でしたが、AWSのマネージドサービスを使うことで「インフラ運用不要」「自動スケール」「セキュリティ強化」などのメリットが得られます。OSSの柔軟性とAWSクラウドの安定性・運用効率を両立できるのが大きな魅力です。
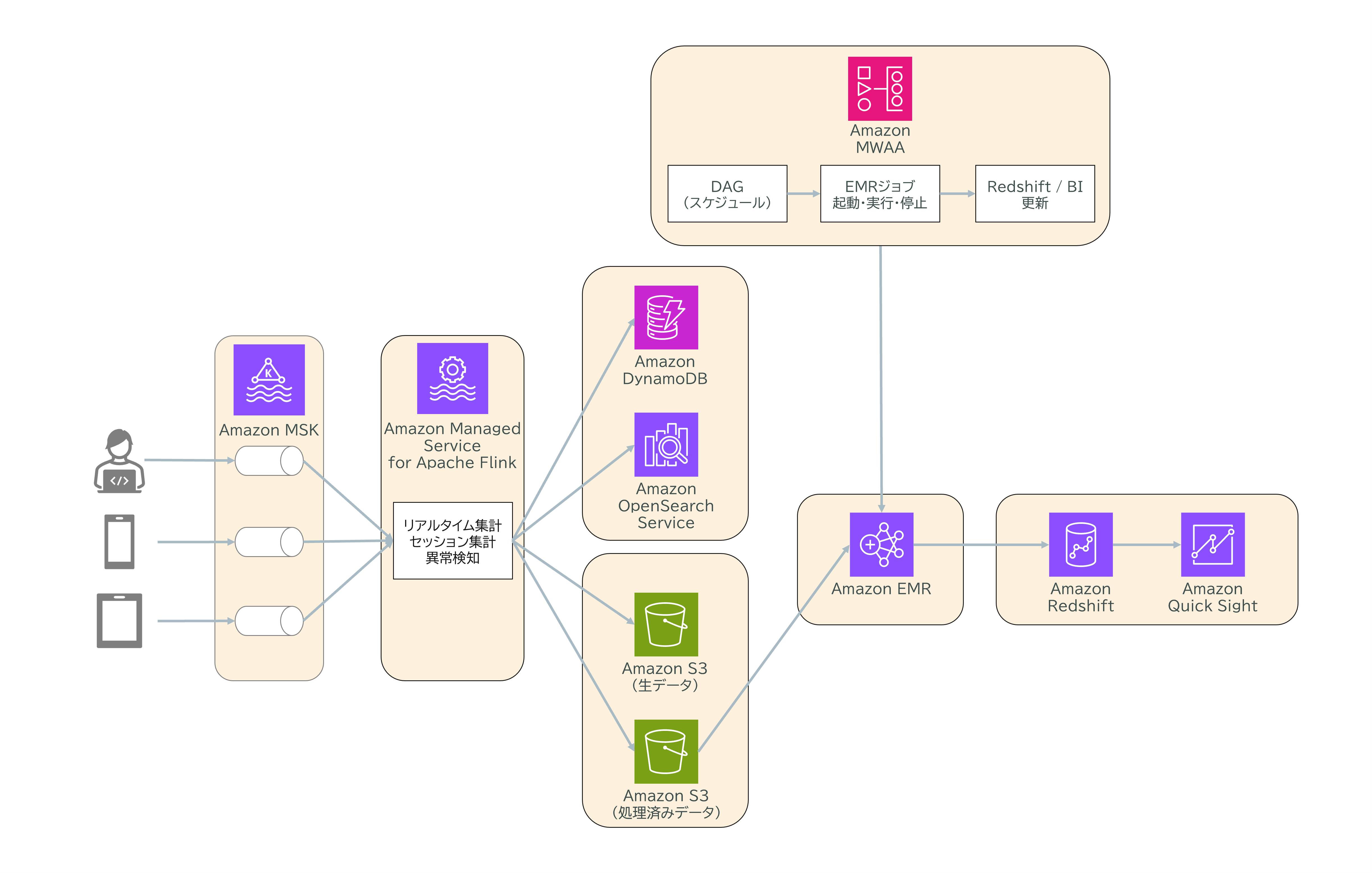
Apache Kafka・Flink・Airflowのシステム連携イメージ
これらを一つのシステムとして組み合わせると、下記のような流れになります。
- Kafka:様々な端末やシステムからストリームデータ(ログやイベント)を収集します。
- Flink:Kafkaで収集したデータをリアルタイムで集計・セッション分析・異常検知などのストリーム処理を行います。
- Airflow:DAG(有向非巡回グラフ)によるスケジューラで、EMRジョブの起動・実行・停止やRedshift/BIツールの更新など、バッチ処理や分析の全体フローを管理します。
この構成では、
- 生データや処理済みデータはS3などに保管
- 集計データはDynamoDBやOpenSearch Serviceに保存・可視化
- バッチ分析や日次処理はEMRやRedshift、QuickSightなどで実施
といった流れを実現できます。
画像の例では、Kafka→Flink→DynamoDB/OpenSearch/S3→Airflow→EMR/Redshift/QuickSightという連携が描かれています。
Kinesis Data StreamsとApache Kafkaの違いと使い分け
「Kinesis Data Streams」と「Apache Kafka」は、どちらもストリームデータの収集・分配を担いますが、用途や連携先によって使い分けが重要です。
Amazon Kinesis Data Streams
- AWS上で新規にリアルタイム基盤を構築したい場合に最適
- 運用を極力シンプルにしたい場合
- 主な連携先がAWSサービス(Lambda、Firehose、S3など)の場合

Amazon MSK(Managed Streaming for Apache Kafka)
- すでにKafkaを社内で利用している、資産を活かしたい場合
- マイクロサービス間のイベント基盤をKafkaで統一したい場合
- オンプレミスや他クラウドとKafkaプロトコルで連携したい場合

ワークフロー管理サービス(Airflow・Step Functions・Glue Workflow)の比較
ワークフロー管理サービスとして、「MWAA(Managed Airflow)」「Step Functions」「Glue Workflow」があります。それぞれの特徴や向いているケースをまとめると、下記の通りです。
Airflowは複数タスクを順序/依存関係を持って実行、Step Functionsは状態遷移や分岐を管理、Glue WorkflowはETLジョブの順序管理に特化していることが分かります。
Amazon MWAA

- Apache Airflowによるワークフロー基盤(データ/ML寄り)
- Python DAGで柔軟に制御
強み・向いているケース
- Airflowエコシステム・複雑な依存関係に強い
- 既存Airflow環境との統一、MLパイプラインなど
AWS Step Functions

- サーバーレスなワークフロー・ステートマシン
- AWSサービス連携が豊富
強み・向いているケース
- 高信頼性・状態管理・分岐/リトライ/承認フローなど
- Lambda/API/バッチ処理をまたぐワークフロー
AWS Glue Workflow

- Glueジョブ/クローラー用の簡易オーケストレーション
強み・向いているケース
- Glueに特化・セットアップが楽
- Glueジョブ+Crawlerで完結するETLパイプライン



