AWS DEA実践シリーズ① ETL関連サービス | Glue, Glue DataBrew, Athena, Redshift
このシリーズでは、社内で実施した「AWS DEA勉強会」の内容を元に、AWSのデータ関連サービスを解説します。勉強会ではサービスの特徴のご紹介の後、実際の問題の解説や環境でのデモを通して、実践的に学ぶ形式で行いました。連載第1弾は、Glue・DataBrew・Athena・Redshiftについてご紹介します。
AWS DEAシリーズのすべての記事はこちらから

今回のテーマと全体像
今回取り上げる主なAWSサービスは以下の4つです。
- AWS Glue
- AWS Glue DataBrew
- Amazon Athena
- Amazon Redshift
これらはAWSのデータ分析基盤を構成する重要なサービスであり、ETLを実装するための「データの準備・加工・分析」を効率的に行うために活用されます。
サービス | 主な用途 | 特徴 |
|---|---|---|
AWS Glue | データ抽出・変換・ロード | ノーコードETL、カタログ化 |
AWS Glue DataBrew | データクレンジング・前処理 | GUI操作、品質レポート |
Amazon Athena | S3データの即席クエリ | サーバーレス、SQL分析 |
Amazon Redshift | 大規模・複雑な分析 | DWH、高速並列処理 |
AWS Glue | マネージドETLサービス

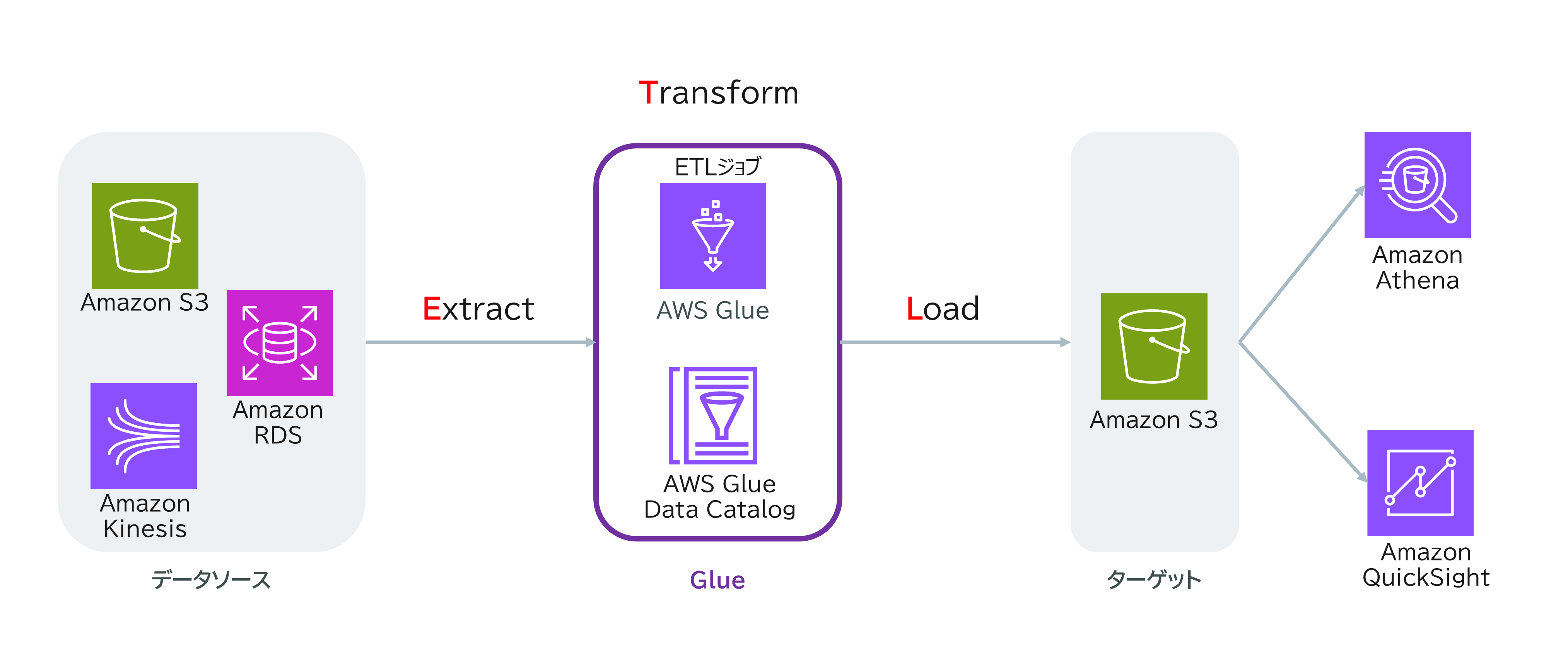
AWS GlueはAWSが提供するマネージドETLサービスです。
ETLとは「Extract(抽出)」「Transform(変換)」「Load(取り込み)」の略で、さまざまなデータソースから情報を抽出し、整形・加工して、他のデータストアに保存する一連のプロセスを指します。
<主なポイント>
- ノーコード/ローコードでETL処理が作成可能
- データのスキーマ検出やカタログ作成も自動化
- きれいに整形されたデータは、分析や可視化に活用できる
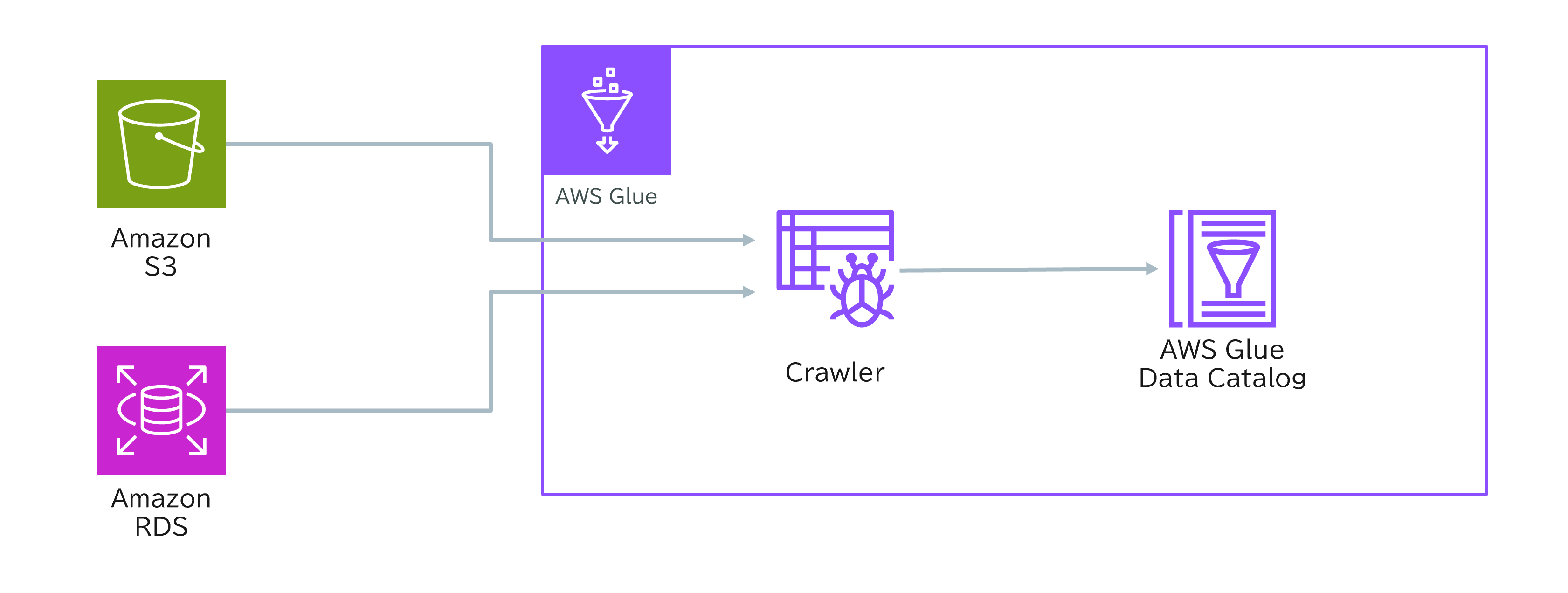
ユースケース:AWS Glue Data CatalogとGlueクローラーによるメタデータ管理の自動化
ある企業は、AWSクラウド上で複数のデータストアを運用しています。これには、Amazon RDSの構造化データや、Amazon S3に保存されたJSONやXMLなどの半構造化データが含まれています。
この企業は、データカタログを定期的に更新し、メタデータの変更を自動で検出したいと考えています。運用負荷を最小限に抑えることも重要な要件です。
解決方法
- AWS Glue Data Catalog をメタデータのリポジトリとして利用します。
- AWS Glueクローラー を設定し、RDSやS3などのデータストアを定期的にスキャンします。
- クローラーはデータ構造の変更を検出し、Data Catalogを自動で更新します。
ポイント
- 手作業なしでメタデータ管理が自動化され、運用負荷を軽減できます。
- 複数のデータストアのメタデータを一元管理し、常に最新状態を保てます。
このように、Glue Data CatalogとGlueクローラーを組み合わせることで、効率的かつ自動的なメタデータ管理が実現できます。
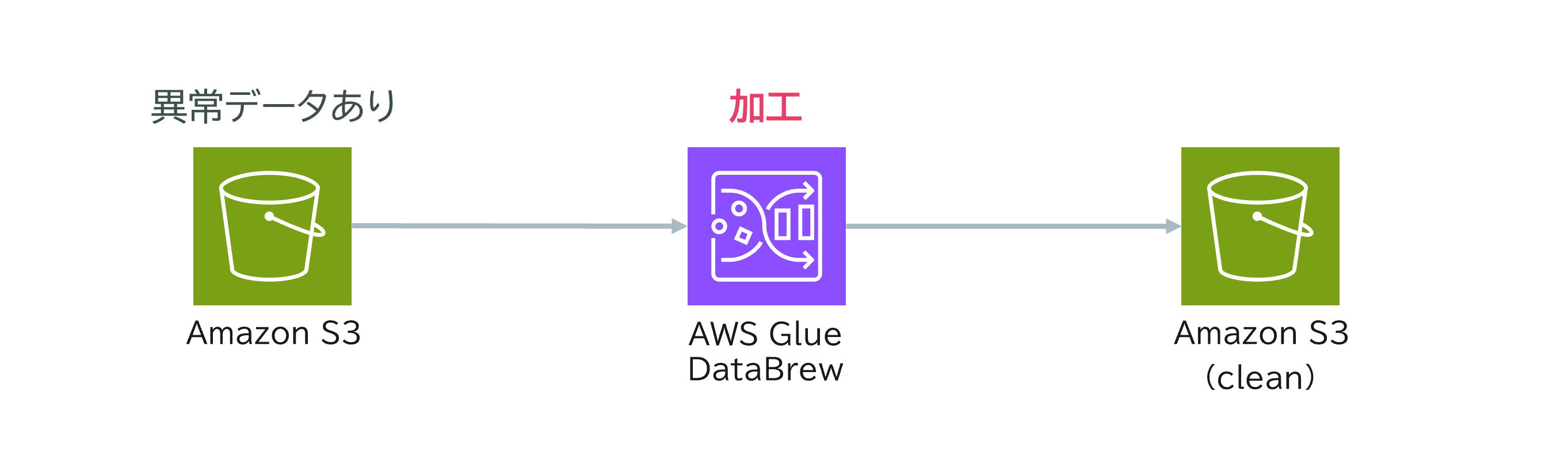
AWS Glue DataBrew | ノーコードデータ前処理

DataBrewはGlueファミリーのノーコードデータ準備ツールです。GUIベースでデータのクリーニングや変換、可視化ができます。
<主なポイント>
- SQLやPythonの知識不要でデータクレンジングが可能
- 欠損値や異常値、重複データの除去もドラッグ&ドロップで設定
- データ品質の可視化・レポート機能も充実
ユースケース:AWS Glue DataBrewによるノーコード・データクレンジング
ある衣料品メーカーでは、Amazon S3バケットに複数のファイルとしてユーザーの行動ログやイベント情報などの生データ(JSON形式)を保存し、処理・分析しています。しかし、これらのデータにはNull値や異常値、重複値が多く、そのままでは正確な分析ができません。
データエンジニアは、できるだけコードを書かず、運用負荷も抑えてデータクレンジングを行いたいと考えています。
解決方法
- AWS Glue DataBrewを使用し、事前にカスタムルール(Null値や異常値、重複値の除去など)を設定します。
- DataBrewのノーコードGUIで、ルールに基づいたデータクレンジングを自動化します。
ポイント
- コーディング不要で、GUI操作だけでデータの品質を向上できます。
- 運用負荷を最小限に抑えつつ、クレンジング済みのきれいなデータを効率よく準備できます。
このように、AWS Glue DataBrewを活用することで、S3に保存された生データの品質を簡単かつ自動的に向上させることができます。
Amazon Athena | サーバーレスSQLクエリエンジン

Athenaはサーバーレスのインタラクティブクエリエンジンです。Amazon S3上のデータを直接SQLでクエリできます。
<主なポイント>
- S3にある構造化・半構造化・非構造化データを直接クエリ
- インフラ管理不要、利用した分だけ課金
- ちょっとしたデータ確認や検索に最適
ユースケース:S3のParquetデータを効率的に分析する方法
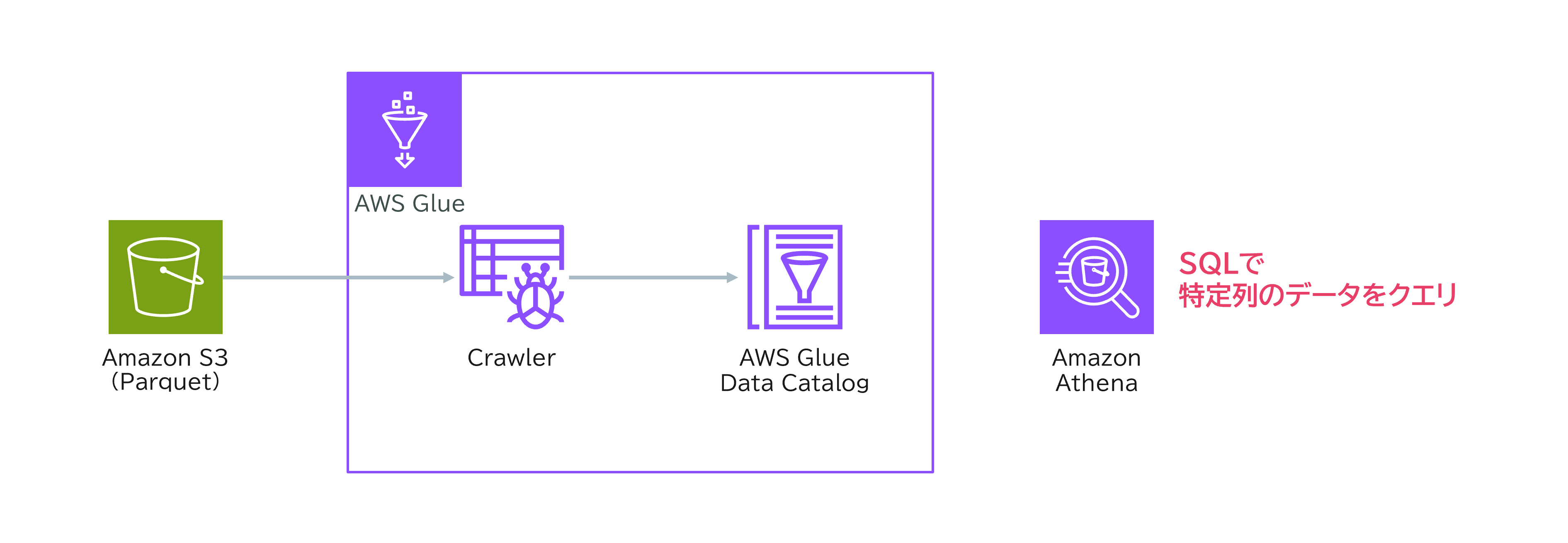
国際展開するアパレル小売企業では、各店舗の売上データをAmazon S3バケットに集約して管理しています。データエンジニアは、このS3内のApache Parquet形式の販売データから、特定の列だけを抽出して分析する必要があります。できるだけ運用負担を減らしたいという要件です。
解決方法
- AWS Glueクローラーを使い、S3のParquetデータからメタデータ(スキーマ情報)を自動で作成します。
- 作成されたメタデータをもとに、Amazon AthenaでSELECT文を実行し、必要な列だけをクエリします。
ポイント
- Parquet形式は「列指向」なので、欲しい列(例:price)だけを効率よく読み取れます。
- GlueクローラーとAthenaを組み合わせることで、手作業なしで管理・分析が可能です。
- 運用負担が最小限になり、データ抽出も高速です。
このように、GlueクローラーとAthenaを活用することで、S3上のParquetデータから必要な列だけを効率よく分析でき、運用も簡単にできます。
Amazon Redshift | ペタバイト規模のDWH

Redshiftはペタバイト級のデータを高速分析できるデータウェアハウスです。
<主なポイント>
- S3のデータをRedshiftクラスタにロードして、高速かつ大規模な分析が可能
- 並列分散処理による高パフォーマンス
- 複雑な分析や大量データの集計に最適
- 取り扱いは基本的に「構造化データ」が対象
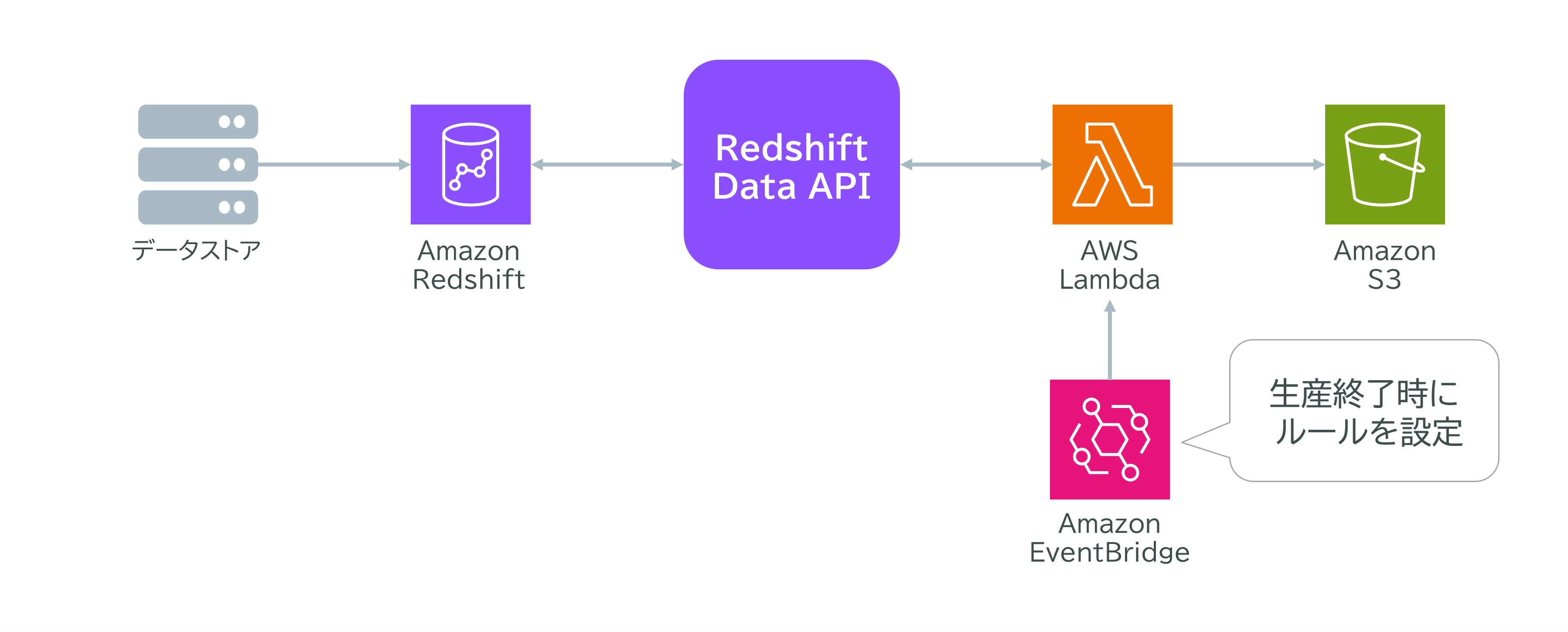
ユースケース:Redshift・Lambda・EventBridgeによる自動データ公開
あるプロセス製造企業では、自社プラントの毎日の生産実績をAmazon Redshiftテーブルにロードしています。データエンジニアは、業務終了時刻にRedshift内の特定の列データをS3へ公開したいと考えています。この処理を自動化し、運用負担を減らすことが求められています。
解決方法
- Amazon EventBridgeで業務終了時刻に合わせてスケジュールルールを設定します。
- EventBridgeがAWS Lambda関数を自動起動します。
- Lambda関数内でAmazon Redshift Data APIを使い、Redshiftテーブルから必要な列データを取得します。
- Lambdaが取得したデータをAmazon S3へ保存します。
ポイント
- スケジュール実行なので、手作業や管理の手間がありません。
- Redshift Data APIを使うことで、Lambdaから直接データ取得が可能です。
- S3にデータを公開することで、他システムやユーザーと簡単に共有できます。
このように、EventBridge・Lambda・Redshift Data API・S3を組み合わせることで、業務終了時刻に自動でデータを取得し、公開する仕組みを簡単に構築できます。